
This summer I had the unforgettable opportunity to work side-by-side with the some of the smartest, photography-loving software engineers I’ve ever met. Looking back on my first day at Flickr HQ – beginning with a harmonious welcome during Flickr Engineering’s weekly meeting – I can confidently say that over the past ten weeks I have become a much better software engineer.
One of my projects for the summer was to build a new and improved locking manager that controls the distribution of locks for offline tasks (or OLTs for short). Flickr uses OLTs all the time for data migration, uploading photos, updates to accounts, and more. An OLT needs to acquire a lock on a shared resource, such as a group or an account, to prevent other OLTs from accessing the same resource at the same time. The OLT will then release the lock when it’s done modifying the shared data. Myles wrote an excellent blog post on how Flickr uses offline tasks here.
When building a distributed lock system, we need to take into account a couple of important details. First, we need to make sure that all the lock servers are consistent. One way to maintain consistency is to elect one server to act as a master and the remaining servers as slaves, where the master server is responsible for data replication among the slave servers. Second, we need to account for network and hardware failures – for instance, if the master server goes down for some reason, we need to quickly elect a new master server from one of the slave servers. The good news is, Apache ZooKeeper is an open-source implementation of master-slave data replication, automatic leader election, and atomic distributed data reads and writes.
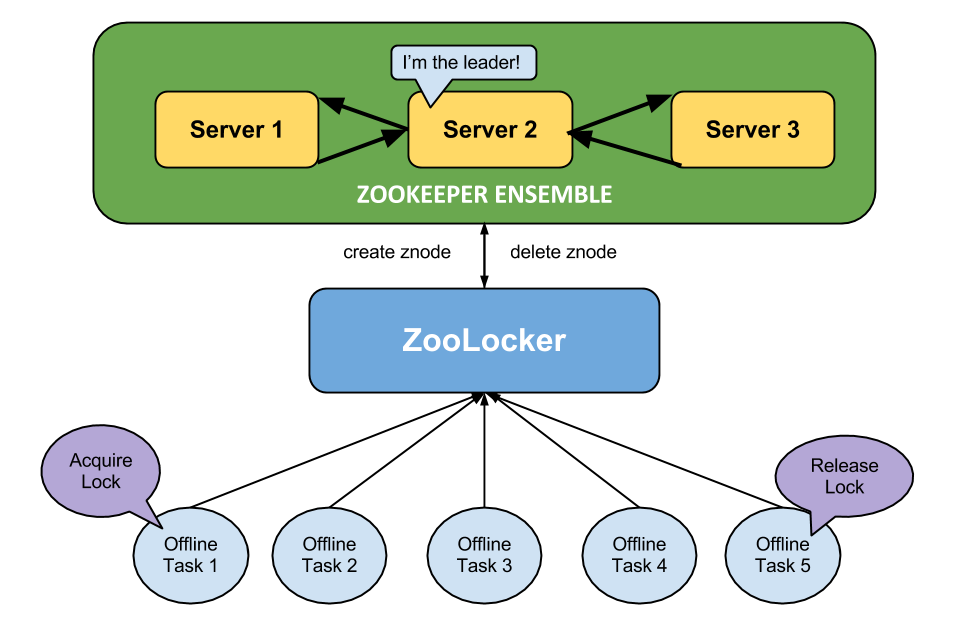
Offline tasks send lock acquire and release requests through ZooLocker. ZooLocker in turn interfaces with the ZooKeeper cluster to create and delete znodes that correspond to the individual locks.
In the new locking system (dubbed “ZooLocker”), each lock is stored as a unique data node (or znode) on the ZooKeeper servers. When a client acquires a lock, ZooLocker creates a znode that corresponds to the lock. If the znode already exists, ZooLocker will tell the client that the lock is currently in use. When a client releases the lock, ZooLocker deletes the corresponding znode from memory. ZooLocker stores helpful debugging information, such as the owner of the lock, the host it was created on, and the maximum amount of time to hold on to the lock, in a JSON-serialized format in the znode. ZooLocker also periodically scans through each znode in the ZooKeeper ensemble to release locks that are past their expiration time.
My locking manager is already serving locks in production. In spite of sudden spikes in lock acquire and release requests by clients, the system holds up pretty well.
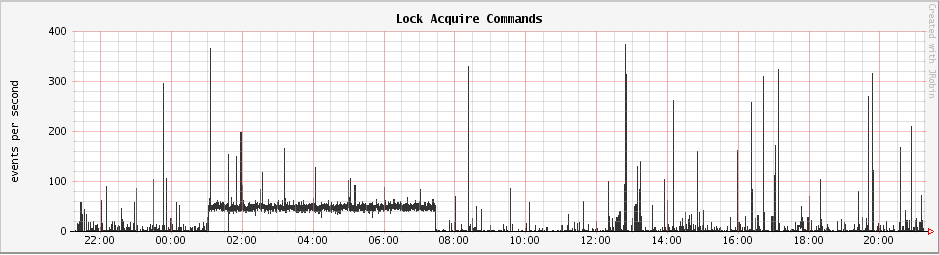
A graph of the number of lock acquire requests in ZooLocker per second
My summer internship at Flickr has been an incredibly valuable experience for me. I have demystified the process of writing, testing, and integrating code into a running system that millions of people around the world use each and every day. I have also learned about the amazing work going on in the engineering team, the ups and downs the code deploy process, and how to dodge the incoming flying finger rockets that the Flickr team members fling at each other. My internship at Flickr is an experience I will never forget, and I am very grateful to the entire Flickr team for giving me the opportunity to work and learn from them this summer.