
We recently implemented Redis Sentinel at Flickr to provide automated Redis master failover for an important subsystem and we wanted to share our experience with it. Hopefully, we can provide insight into our experience adopting this relatively new technology and some of the nuances we encountered getting it up and running. Although we try to provide a basic explanation of what Sentinel is and how it works, anyone who is new to Redis or Sentinel should start with the excellent Redis and Sentinel documentation.
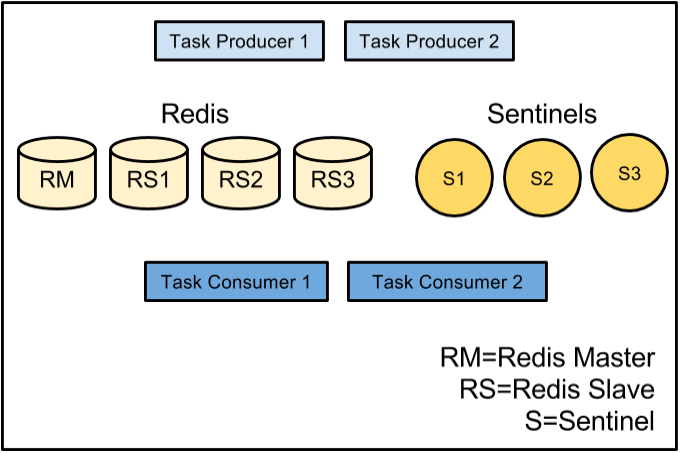
At Flickr we use an offline task processing system that allows us to execute heavyweight operations asynchronously from our API and web pages. This prevents these operations from making users wait needlessly for pages to render or API methods to return. Our task system handles millions of tasks per day which includes operations like photo uploads, user notifications and metadata edits. In this system, code can push a task onto one of several Redis-backed queues based on priority and operation, then forget about the task. Many of these operations are critical and we need to make sure we process at least 99.9999% of them (less than 1 in 1 million dropped). Additionally, we need to make sure this system is available to insert and process tasks at least 99.995% of the time – no more than about 2 minutes a month downtime.
Until a few months ago our Redis BCP consisted of:
- Redis append-only-files (AOF)
- Warm-swappable slaves
- Logging task insert failures
Upon master failure, the recovery plan included several manual steps: reconfiguring code to take the Redis master(s) offline and manually promoting a Redis slave (a mildly time consuming activity). Then we would rebuild and backfill unprocessed data from AOF files and error logs — a very time consuming activity. We knew if we lost a master we would have hours and hours of less-than-satisfying work to run the recovery plan, and there was potential for user impact and even a small amount of data loss. We had never experienced a Redis master failure, but we all know that such events are simply a matter of time. Overall, this fell far short of our durability and availability goals.
Configuring Sentinel
We started by installing and testing Sentinel in a development environment and the first thing we noticed was how simple Sentinel is to use and how similar the syntax is to Redis. We read Aphyr’s article and his back-and-forth blog duel with Salvatore and verified Aphyr’s warning about the “split brain” scenario. Eventually we decided the benefits outweighed the risks in our specific use case. During testing we learned about some Sentinel nuances and got a better feel for appropriate configuration values, many of which have little or no community guidance yet.
One such example was choosing a good value for the level-of-agreement setting, which is the number of Sentinels simultaneously reporting a host outage before automatic failover starts. If this value is too high then you’ll miss real failures and if it’s too low you are more susceptible to false alarms. (*thanks to Aleksey Asiutin(@aasiutin) for the edit!) In the end, we looked at the physical topology of our hosts over rack and switches and chose to run a relatively large number of Sentinel instances to ensure good coverage. Based on tuning in production we chose a value for level-of-agreement equal to about 80% of the Sentinel instances.
The down-after-milliseconds configuration setting is the time the Sentinels will wait with no response to their ping requests before declaring a host outage. Sentinels ping the hosts they monitor approximately every second, so by choosing a value of 3,100 we expect Sentinels to miss 3 pings before declaring host outage. Interestingly, because of Sentinel’s ping frequency we found that setting this value to less than 1,000 results in an endless stream of host outage notifications from the Sentinels, so don’t do that. We also added an extra 100 milliseconds (3,100ms rather than 3,000ms) to allow for some variation in Redis response time.
We chose a parallel-syncs value of 1. This item dictates the number of slaves that are reconfigured simultaneously after a failover event. If you serve queries from the read-only slaves you’ll want to keep this value low.
For an explanation of the other values we refer you to the self-documented default sentinel.conf file.
An example of the Sentinel configuration we use:
sentinel monitor cluster_name_1 redis_host_1 6390 35 sentinel down-after-milliseconds cluster_name_1 3100 sentinel parallel-syncs cluster_name_1 1 sentinel monitor cluster_name_2 redis_host_2 6391 35 sentinel down-after-milliseconds cluster_name_2 3100 sentinel parallel-syncs cluster_name_2 1 port 26379 pidfile [path]/redis-sentinel.pid logfile [path]logs/redis/redis-sentinel.log daemonize yes
An interesting nuance of Sentinels is that they write state to their configuration file. This presented a challenge for us because it conflicted with our change management procedures. How do we maintain a dependably consistent startup configuration if the Sentinels are modifying the config files at runtime? Our solution was to create two Sentinel config files. One is strictly maintained in Git and not modified by Sentinel. This “permanent” config file is part of our deployment process and is installed whenever we update our Sentinel system configuration (i.e.: “rarely”). We then wrote a startup script that first duplicates the “permanent” config file to a writable “temporary” config file, then starts Sentinel and passes it the “temporary” file via command-line params. Sentinels are allowed to modify the “temporary” files as they please.

Interfacing with Sentinel
A common misconception about Sentinel is that it resides in-band between Redis and Redis clients. In fact, Sentinel is out-of-band and is only contacted by your services on startup. Sentinel then publishes notifications when it detects a Redis outage. Your services subscribe to Sentinel, receive the initial Redis host list, and then carry on normal communication directly with the Redis host.
The Sentinel command syntax is very similar to Redis command syntax. Since Flickr has been using Redis for a long time the adaptation of pre-existing code was pretty straightforward for us. Code modifications consisted of adding a few Java classes and modifying our configuration syntax. For Java-to-Redis interaction we use Jedis, and for PHP we use Predis and libredis.
Using Sentinel from Jedis is not documented as well as it could be. Here’s some code that we hope will save you some time:
// Verify that at least one Sentinel instance in the Set is available and responding.
// sentinelHostPorts: String format: [hostname]:[port]
private boolean jedisSentinelPoolAvailable(Set<String> sentinelHostPorts, String clusterName){
log.info("Trying to find master from available Sentinels...");
for ( String sentinelHostPort : sentinelHostPorts ) {
List<String> hostPort = Arrays.asList( sentinelHostPort.split(":") );
String hostname = hostPort.get(0);
int port = Integer.parseInt( hostPort.get(1) );
try {
Jedis jedis = new Jedis( hostname, port );
jedis.sentinelGetMasterAddrByName( clusterName );
jedis.disconnect();
log.info("Connected to Sentinel host:%s port:%d", hostname, port);
return true;
} catch (JedisConnectionException e) {
log.warn("Cannot connect to Sentinel host:%s port:%d”, hostname, port);
}
}
return false;
}
private Pool<Jedis> getDefaultJedisPool() {
// Create and return a default Jedis Pool object…
// ...
}
// ConfigurationMgr configMgr ⇐ your favorite way of managing system configuration (up to you)
public Pool<Jedis> getPool(ConfigurationMgr configMgr) {
String clusterName = configMgr.getRedisClusterName();
Set<String> sentinelHostPorts = configMgr.getSentinelHostPorts();
if(sentinels.size()>0) {
if(jedisSentinelPoolAvailable( sentinelHostPorts, clusterName )) {
return new JedisSentinelPool(clusterName, sentinelHostPorts);
} else {
log.warn(“All Sentinels unreachable. Using default Redis hosts.”);
return getDefaultJedisPool();
}
} else {
log.warn(“Sentinel config empty. Using default Redis hosts.”);
return getDefaultJedisPool();
}
}
Testing Sentinel at Flickr
Before deploying Sentinel to our production system we had several questions and concerns:
- How will the system react to host outages?
- How long does a failover event last?
- How much of a threat is the split-brain scenario?
- How much data loss can we expect from a failover?
We commandeered several development machines and installed a few Redis and Sentinel instances. Then we wrote some scripts that insert or remove data from Redis to simulate production usage.
We ran a series of tests on this setup, simulating a variety of Redis host failures with some combination of the commands: kill -9, the Sentinel failover command, and Linux iptables. This resulted in “breaking” the system in various ways.
 Figure: Redis master failure
Figure: Redis master failure
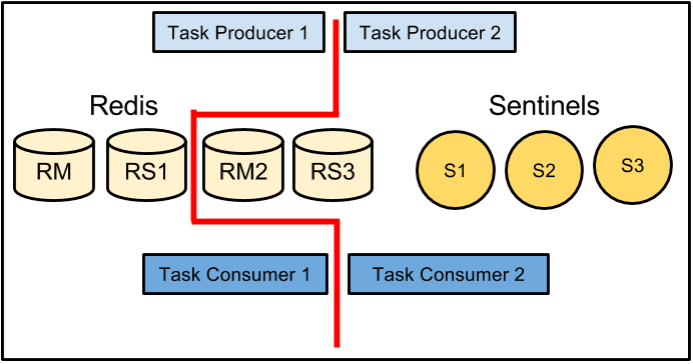
Figure: Network partition producing a ‘split-brain’ scenario
How will the system react to host outages?
For the most part we found Sentinel to behave exactly as expected and described in the Sentinel docs. The Sentinels detect host outages within the configured down-after-milliseconds duration, then send “subjective down” notifications, then send “objective down” notifications if the level-of-agreement threshold is reached. In this environment we were able to quickly and accurately test our response to failover events. We began with small test scripts, but eventually were able to run repeatable integration tests on our production software. Adding Redis to a Maven test phase for automated integration testing is a backlog item that we haven’t implemented yet.
How long does a failover event last?
The Sentinel test environment was configured with a down-after-milliseconds value of 3,100ms (just like production, see above). With this value Sentinels would produce a host outage notification after approximately 3 unsuccessful pings (one ping per second). In addition to the 3,100ms delay, we found there were 1-3 seconds in overhead for processing the failover event and electing a new Redis master, resulting in 4-6 seconds of total downtime. We are pretty confident we’ll see the same behavior in production (verified — see below).
How much of a threat is the “split-brain” scenario?
We carefully read Aphyr and Salvatore’s blog articles debating the threat of a “split brain scenario.” To summarize: this is a situation in which network connectivity is split, with some nodes still functioning on one side and other nodes continuing to function independently on the other side. The concern is the potential for the data set to diverge with different data being written to masters on both sides of the partition. This could easily create data that is either impossible or very difficult to reconcile.
We recreated this situation and verified that a network partition could create disjoint concurrent data sets. Removing the partition resulted in Sentinel arbitrarily (from our perspective) choosing a new master and losing all data written (post-partitioning) to the other master. So the question is: given our production architecture, what is the probability of this happening and is it acceptable given the significant benefit of automatic failover?
We looked at this scenario in detail considering all the potential failure modes in our deployment. Although we believe our production environment is not immune from split-brain, we are pretty sure that the benefits outweigh the risks.
How much data loss can we expect from a failover event?
After testing we were confident that Redis host outages could produce 4-6 seconds of downtime in this system. Rapid Sentinel automated failover events combined with reasonable backoff and retry techniques in the code logic were expected to further reduce data loss during a failover event. With Sentinel deployed and considering a long history of a highly stable Redis operation, we believed we could achieve 99.995% or more production availability – a few minutes of downtime per year.
Sentinel in Production
So how has Sentinel performed in production? Mostly it has been silent, which is a good thing. A month after finishing our deployment we had a hardware failure in a network switch that had some of our Redis masters behind it. Instead of having a potential scenario involving tens of minutes of user impact with human-in-the-loop actions to restore service, automatic failover allowed us to limit impact to just seconds with no human intervention. Due to the quick master failover and other reliability features in the code, only 270 tasks failed to insert due to the outage — all of which were captured by logging. Based on the volume of tasks in the system, this met our 99.9999% task durability goal. We did however decide to re-run a couple tasks manually and for certain critical and low-volume tasks we’re looking at providing even more reliability.
One more note from production experience. We occasionally see Sentinels reporting false “subjective down” events. Our Sentinel instances cohabitate host machines with other services. Occasionally these hosts get busy and we suspect these occasional load spikes affect the Sentinels’ ability to send and receive ping requests. But because our level-of-agreement is high, these false alarms do not trigger objective down events and are relatively harmless. If you’re deploying Sentinel on hosts that share other workloads, make sure that you consider potential impact of load patterns on those hosts and make sure you take some time to tune your level-of-agreement.
Conclusion
We have been very happy with Sentinel’s ease of use, relatively simple learning curve and brilliant production execution. So far the Redis/Sentinel combination is working great for us.

Like this post? Have a love of online photography? Want to work with us? Flickr is hiring engineers, designers and product managers in our San Francisco office. Find out more at flickr.com/jobs.
References
- Redis Sentinel Documentation – http://redis.io/topics/sentinel
- Redis Command Reference – http://redis.io/commands
- Aphyr: Call me maybe: Redis – http://aphyr.com/posts/283-call-me-maybe-redis
- Antirez: Reply to Aphyr Attack on Sentinel – http://antirez.com/news/55
- Jedis Project Page – https://github.com/xetorthio/jedis
Pingback: Consideraciones al implementar cache en aplicaciones | beljebuzz
Pingback: ObjectRocket Adds Fully-Managed Redis Service - Web Hosting Blog