
One of the largest cost drivers in running a service like Flickr is storage. We’ve described multiple techniques to get this cost down over the years: use of COS, creating sizes dynamically on GPUs and perceptual compression. These projects have been very successful, but our storage cost is still significant.
At the beginning of 2016, we challenged ourselves to go further — to go a full year without needing new storage hardware. Using multiple techniques, we got there.
The Cost Story
A little back-of-the-envelope math shows storage costs are a real concern. On a very high-traffic day, Flickr users upload as many as twenty-five million photos. These photos require an average of 3.25 megabytes of storage each, totalling over 80 terabytes of data. Stored naively in a cloud service similar to S3, this day’s worth of data would cost over $30,000 per year, and continue to incur costs every year.
And a very large service will have over two hundred million active users. At a thousand images each, storage in a service similar to S3 would cost over $250 million per year (or $1.25 / user-year) plus network and other expenses. This compounds as new users sign up and existing users continue to take photos at an accelerating rate. Thankfully, our costs, and every large service’s costs, are different than storing naively at S3, but remain significant.
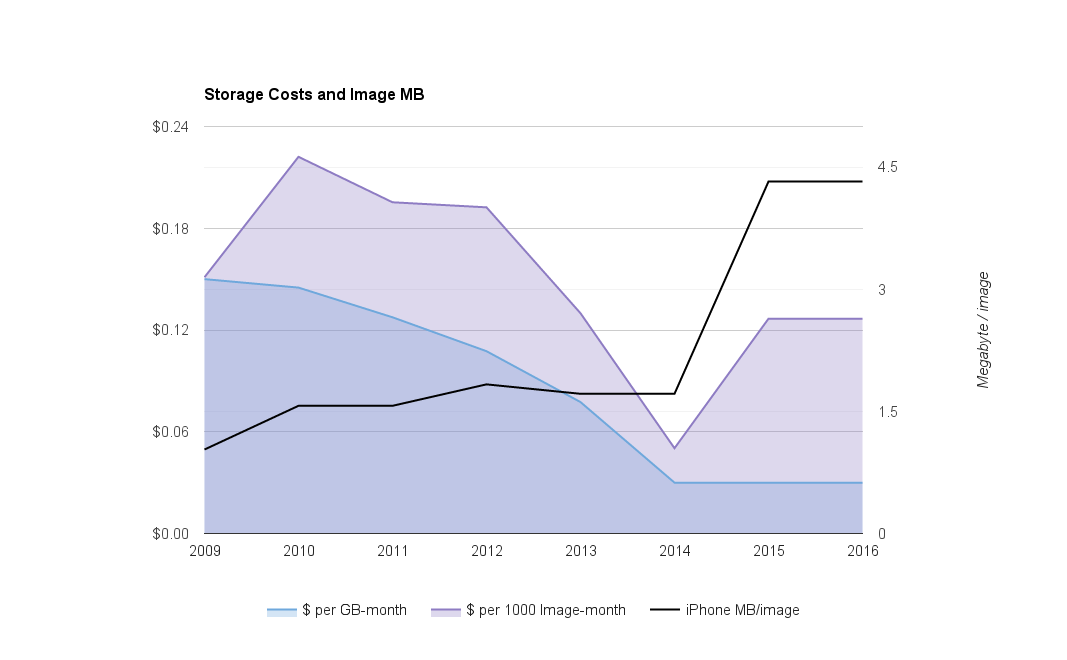
Cost per byte have decreased, but bytes per image from iPhone-type platforms have increased. Cost per image hasn’t changed significantly.
Storage costs do drop over time. For example, S3 costs dropped from $0.15 per gigabyte month in 2009 to $0.03 per gigabyte-month in 2014, and cloud storage vendors have added low-cost options for data that is infrequently accessed. NAS vendors have also delivered large price reductions.
Unfortunately, these lower costs per byte are counteracted by other forces. On iPhones, increasing camera resolution, burst mode and the addition of short animations (Live Photos) have increased bytes-per-image rapidly enough to keep storage cost per image roughly constant. And iPhone images are far from the largest.
In response to these costs, photo storage services have pursued a variety of product options. To name a few: storing lower quality images or re-compressing, charging users for their data usage, incorporating advertising, selling associated products such as prints, and tying storage to purchases of handsets.
There are also a number of engineering approaches to controlling storage costs. We sketched out a few and cover three that we implemented below: adjusting thresholds on our storage systems, rolling out existing savings approaches to more images, and deploying lossless JPG compression.
Adjusting Storage Thresholds
As we dug into the problem, we looked at our storage systems in detail. We discovered that our settings were based on assumptions about high write and delete loads that didn’t hold. Our storage is pretty static. Users only rarely delete or change images once uploaded. We also had two distinct areas of just-in-case space. 5% of our storage was reserved space for snapshots, useful for undoing accidental deletes or writes, and 8.5% was held free in reserve. This resulted in about 13% of our storage going unused. Trade lore states that disks should remain 10% free to avoid performance degradation, but we found 5% to be sufficient for our workload. So we combined our our two just-in-case areas into one and reduced our free space threshold to that level. This was our simplest approach to the problem (by far), but it resulted in a large gain. With a couple simple configuration changes, we freed up more than 8% of our storage.

Adjusting storage thresholds
Extending Existing Approaches
In our earlier posts, we have described dynamic generation of thumbnail sizes and perceptual compression. Combining the two approaches decreased thumbnail storage requirements by 65%, though we hadn’t applied these techniques to many of our images uploaded prior to 2014. One big reason for this: large-scale changes to older files are inherently risky, and require significant time and engineering work to do safely.
Because we were concerned that further rollout of dynamic thumbnail generation would place a heavy load on our resizing infrastructure, we targeted only thumbnails from less-popular images for deletes. Using this approach, we were able to handle our complete resize load with just four GPUs. The process put a heavy load on our storage systems; to minimize the impact we randomized our operations across volumes. The entire process took about four months, resulting in even more significant gains than our storage threshold adjustments.
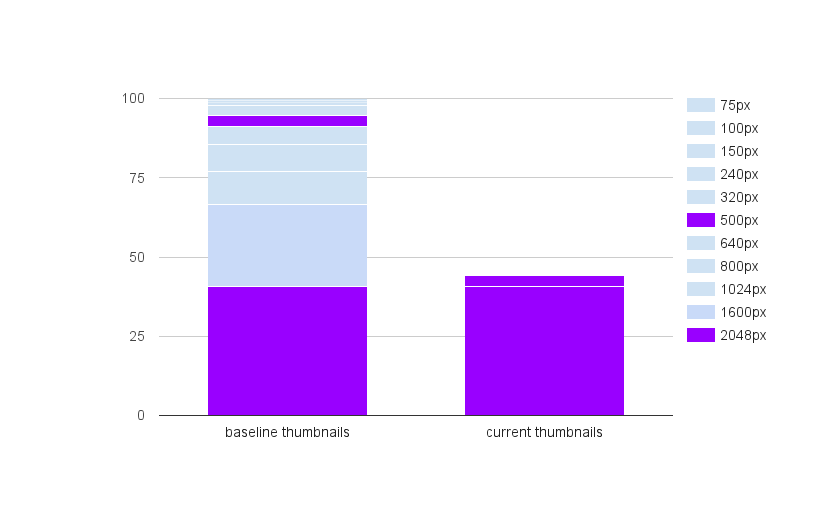
Decreasing the number of thumbnail sizes
Lossless JPG Compression
Flickr has had a long-standing commitment to keeping uploaded images byte-for-byte intact. This has placed a floor on how much storage reduction we can do, but there are tools that can losslessly compress JPG images. Two well-known options are PackJPG and Lepton, from Dropbox. These tools work by decoding the JPG, then very carefully compressing it using a more efficient approach. This typically shrinks a JPG by about 22%. At Flickr’s scale, this is significant. The downside is that these re-compressors use a lot of CPU. PackJPG compresses at about 2MB/s on a single core, or about fifteen core-years for a single petabyte worth of JPGs. Lepton uses multiple cores and, at 15MB/s, is much faster than packJPG, but uses roughly the same amount of CPU time.
This CPU requirement also complicated on-demand serving. If we recompressed all the images on Flickr, we would need potentially thousands of cores to handle our decompress load. We considered putting some restrictions on access to compressed images, such as requiring users to login to access original images, but ultimately found that if we targeted only rarely accessed private images, decompressions would occur only infrequently. Additionally, restricting the maximum size of images we compressed limited our CPU time per decompress. We rolled this out as a component of our existing serving stack without requiring any additional CPUs, and with only minor impact to user experience.
Running our users’ original photos through lossless compression was probably our highest-risk approach. We can recreate thumbnails easily, but a corrupted source image cannot be recovered. Key to our approach was a re-compress-decompress-verify strategy: every recompressed image was decompressed and compared to its source before removing the uncompressed source image.
This is still a work-in-progress. We have compressed many images but to do our entire corpus is a lengthy process, and we had reached our zero-new-storage-gear goal by mid-year.
On The Drawing Board
We have several other ideas which we’ve investigated but haven’t implemented yet.
In our current storage model, we have originals and thumbnails available for every image, each stored in two datacenters. This model assumes that the images need to be viewable relatively quickly at any point in time. But private images belonging to accounts that have been inactive for more than a few months are unlikely to be accessed. We could “freeze” these images, dropping their thumbnails and recreate them when the dormant user returns. This “thaw” process would take under thirty seconds for a typical account. Additionally, for photos that are private (but not dormant), we could go to a single uncompressed copy of each thumbnail, storing a compressed copy in a second datacenter that would be decompressed as needed.
We might not even need two copies of each dormant original image available on disk. We’ve pencilled out a model where we place one copy on a slower, but underutilized, tape-based system while leaving the other on disk. This would decrease availability during an outage, but as these images belong to dormant users, the effect would be minimal and users would still see their thumbnails. The delicate piece here is the placement of data, as seeks on tape systems are prohibitively slow. Depending on the details of what constitutes a “dormant” photo these techniques could comfortably reduce storage used by over 25%.
We’ve also looked into de-duplication, but we found our duplicate rate is in the 3% range. Users do have many duplicates of their own images on their devices, but these are excluded by our upload tools. We’ve also looked into using alternate image formats for our thumbnail storage. WebP can be much more compact than ordinary JPG but our use of perceptual compression gets us close to WebP byte size and permits much faster resize. The BPG project proposes a dramatically smaller, H.265 based encoding but has IP and other issues.
There are several similar optimizations available for videos. Although Flickr is primarily image-focused, videos are typically much larger than images and consume considerably more storage.
Conclusion
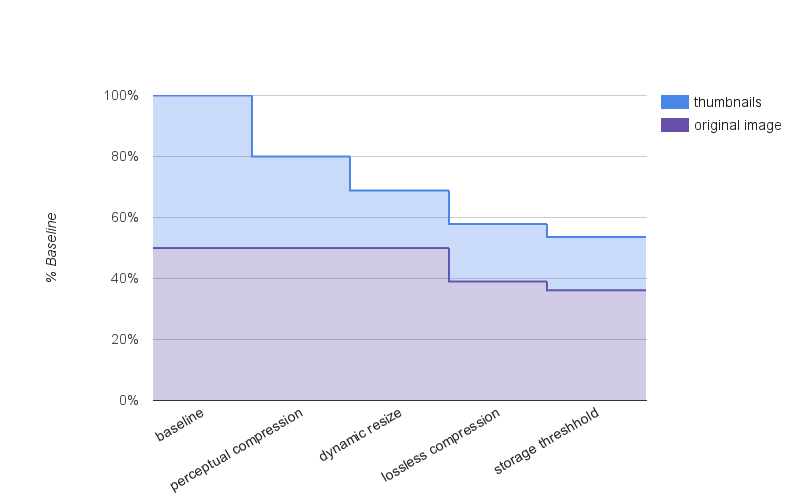
Optimization over several releases
Since 2013 we’ve optimized our usage of storage by nearly 50%. Our latest efforts helped us get through 2016 without purchasing any additional storage, and we still have a few more options available.
Peter Norby, Teja Komma, Shijo Joy and Bei Wu formed the core team for our zero-storage-budget project. Many others assisted the effort.