
When people think about tech and innovation, they often talk about the “next generation.”
Just use GraphQL and life will be easier, many will tell you.
The future of cloud-native is Lambda, claim others.
Unfortunately, most of the conversations don’t talk about the question that is most top-of-mind for me: what does the next generation of tools look like for legacy systems?
As a Senior Engineering Manager for Flickr’s backend team, here’s one of the major issues my team faces: we have a ton of code that engineers need to understand in order to safely and quickly ship changes. Flickr has built a product loved by millions of photographers for nearly two decades and we have some real history in our code base. You can imagine the amount of work it takes to maintain the stability of our large, complex, public-facing API—which impacts not just customers who use our API, but our own web, mobile, and desktop clients.
The difficulty of wrangling a legacy code base is what led us to be interested in Akita, an observability company going after the dream of “one-click” observability. Akita’s first product passively watches API traffic using packet capture (PCAP) to provide automated API monitoring, automatically infer the structure of API endpoints, and automatically detect potential issues and breaking changes. Akita’s goal is to make it possible for organizations like ours, with our hundreds of thousands of lines of legacy code, to understand system behavior in order to move quickly.
But there’s a catch: Akita’s first product, currently in beta, works only for representational state transfer (REST) APIs. Our API at Flickr, nearly twenty years old, coincides with the rise of REST. This blog post focuses on how I used Akita to introduce observability to our code base.
Moving fast with legacy systems
First, let me give some context on high-level responsibilities of backend engineering at Flickr. Since moving Flickr into the cloud two years ago we’ve had more time to focus on modernizing our services and improving our developer experience. This puts us in a much better position to build new features than before—but first, we need to streamline how we get things done, which is not nearly as simple as it sounds.
Today, we serve up around a billion photos daily from millions of photographers. Nearly every Flickr API request executes legacy code in some way—code that is less tested, less documented, and sometimes dangerous to mess with. A great deal of care has to be taken to avoid disruptions. And when new features need to interact with older features, this can get complex fast! On top of all that, we need to find ways to help our small but mighty team focus their limited time and attention while navigating the old and the new, without the luxury of handing this problem over to an internal tools team.
Our difficulty getting a handle on our legacy systems led us to become excited about using Akita for easy observability. Akita promised to tell us about our API interactions and potential issues with the API, all by passively watching API traffic. But there was, as I mentioned, a catch: Akita works only for REST APIs right now, and our API is… RESTish. Most notably, we never adopted the REST convention of using distinct URL paths for each service endpoint, and we rely heavily on passing parameters through the query string, or form-encoded in POSTs. This situation has historically made it hard for us to use other API tools as well.
Getting Akita to work for my REST-like format
Thankfully our PHP request handlers are plug and play so I quickly whipped up a new proof-of-concept handler showing that we could start getting visibility into our API endpoints and their behavior using Akita. This gave me the ability to generate Akita traces using curl and the Akita command line interface (CLI) tool out of the box, but only within my local dev environment.
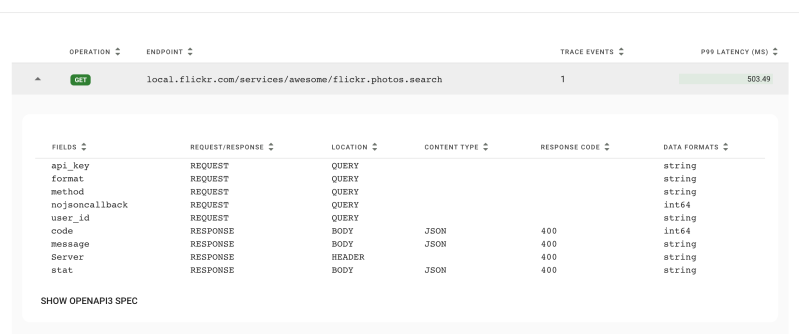
Right away I spotted some things to improve, and more ideas came that afternoon. I wanted to put our `api_key` parameter into an Authorization header, and remove the `method` parameter since I’d used it in a fake service path. Also, our API returns a 200 HTTP Status on errors, including an element `stat` indicating failure. I wanted those to be HTTP 400s.
But I had a conundrum: Akita works best when observing production traffic. Real, production API requests at production load will really fill in the nooks and crannies of our API models. My progress showed it would be so worth it to go further, so I met with the Akita team and discussed using their Go-based plugin system to transform our live requests into a desirable format based on my proof-of-concept. It turns out that most of Akita’s tooling is open source and I could work on the plugin myself! This turned out to be the key to making Akita work with our RESTish format.
Fitting into the Go plugin format
Exciting news! I just needed to turn my prototype into something that I could run with the Akita agent every time.
The Akita CLI has a mechanism for dynamically loading plugins, which can operate on the captured and parsed data before it is sent to the Akita cloud. My transformations of the API format into a more REST-like format could be packaged that way.
I soon discovered that I was the first person to try building a third-party plugin. Akita told me that they used the plugin architecture internally to package a non-open-source plugin that infers data formats, but that is compiled into the client.
My early attempts at working with the released CLI version resulted in nothing but discouraging error messages like:
fatal error: runtime: no plugin module data
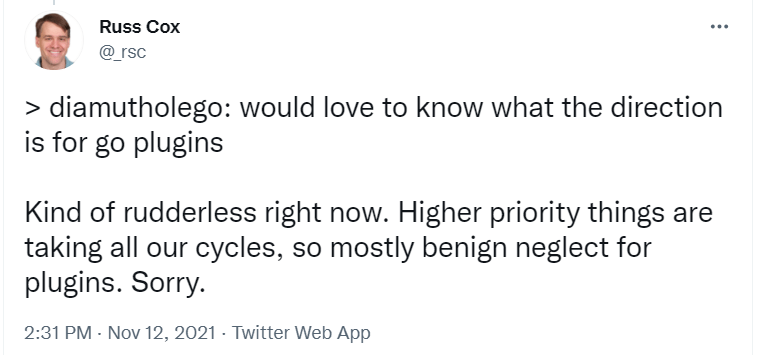
I worked around this by compiling the open-source version of the Akita CLI myself and pointing the plugin build at the exact same version of the source code. An engineer at Akita reported the same problem and concluded that the plugin needed to be built at the same time as the program that will use it. Go’s idiosyncratic linking conventions seem to make it virtually impossible for such an external plugin to satisfy its dependencies against multiple versions of the base binary. Later, we learned the following from Russ Cox, confirming that our decision to abandon the external plugin approach was wise:
https://twitter.com/_rsc/status/1459257455360229387
To make this process repeatable, we adopted a hybrid approach where I added the Flickr-specific transformations of the API as a plugin in a newly created Akita open source repository. (You can check out the code here!) Akita will compile that plugin in all their future CLI builds so there would be no problem with dynamic loading. I can enable the plugin for my traces with a command-line flag and use the most recent version of the CLI without recompiling my plugin to match. This is the same way Akita incorporates modules for type inference. Other users can incorporate contributions in a similar way.
Using Akita to move faster
Now that we have the plugin written, we’re moving toward integration with our production environment. Here’s an example of what we’re able to understand with Akita. Note that the person.new response element has been detected as both datetime and string data types. We should fix that!
Here’s what we’re integrating Akita to do:
- Taking snapshots of our API endpoints. Having a large API footprint makes it all the more important for us to generate defacto specifications and curate the result, rather than try to hand-write specifications from scratch. Once we have a solid OpenAPI3 specification we can make tactical changes to ensure the API adheres to the spec without doing a full-on rewrite of the backend.
- Identifying changes to our API endpoints. The ability to detect unexpected or off-spec responses will make it a lot easier for us to code from the client side, particularly the Android and iOS mobile apps. We expect to reduce defensive exception handling on the client side, making our mobile code easier to work with and less of a resource hog.
- Tracking our inter-service communication as we modernize our infrastructure. Observing the interaction between services is increasingly important as we use more and more microservices and refine our service oriented architecture. For example, having a high level view of impacted services during a production incident will expedite service recovery and get our users back to doing what they love.
While we currently have metrics, monitoring, and logging in place with AWS CloudWatch and Splunk, Akita is able to provide us the information we need in a structured, per-endpoint way, making it easier for our developers to understand what’s going on and focus their attention on what matters. Stay tuned for updates!
Thoughts on tools for legacy systems in general
I see our partnership with Akita as a key part of the beginning of our effort to innovate how to move fast with a legacy system. This problem is not unique to us: Facebook has built multiple type systems for multiple different dynamically typed languages to deal with it! But the fact that we can’t spin off dedicated teams to write compilers for PHP places its own set of constraints. And there are many companies that are in a similar boat: small or medium sized engineering teams of passionate, driven, smart people working on products they love and want you, their customer, to love, too.
I love working on these sorts of problems because they are among the hardest to solve. It takes a lot more than finding a new database or coming up with a faster algorithm; working with large legacy codebases presents challenges that seem intractable. In my experience, you need the right balance of organization, process, tooling, and grit.
Successful companies eventually reach the point where addressing these things is critical and necessary or delivering value slows to a crawl. I’ve found Flickr to be a unique combination of legacy systems, wonderful engineering heritage, and forward-looking, motivated people. If you work somewhere that would benefit from improved production and development observability, you should check out what Akita is up to. And if you’re interested in working with us here, check out the Flickr jobs page!
Many thanks to Jean Yang, Mark Gritter, and the Akita team for their assistance with this post and our integration with their marvelous new product!