

On the last 5 Questions I posted, I ended with “Thank you, Gustavo. Next up (unless Kellan gets in first!) dopiaza.” Well Kellan did indeed get in first, with both Jonnie Hallman and Fraser Speirs. So now, without any more procrastination, I present David Wilkinson, “Utata’s architect” as described by Gustavo …
1. What are you currently building that integrates with Flickr, or a past favorite that you think is cool, neat, popular and worth telling folks about? Or both.
David: I guess one of the most visible things that I’ve built so far is the Utata web site (http://www.utata.org/) and the tools that surround that. Utata, the Flickr group, is a pretty lively community, with over 16,000 members and a pool of over 270,000 photos. In Utata, we like to encourage people to participate, and our web site expands on the group pool and discussion threads on Flickr with a variety of projects for members to participate in, blogs that feature photos picked from the pool, and a wide variety of articles, notices and links. The key thing we’ve tried to do in Utata is to ensure that participation is simple and straightforward. Anyone can come along and join in – the only requirement is that you have a Flickr account.
![]()
Some of the most popular parts of Utata are undoubtedly the group projects – there are typically about three or four group projects in progress at any time, each with their own theme. To take part in a project, all members need to do is tag their photo with the specified project tag and it will then automatically get included in the project pages on the Utata web site. We do all of the hard work of keeping track of which photos are in which project, and presenting the project pages to the world. It is participation made easy – “tag and run”.
To make all that happen, there’s a whole pile of stuff in place behind the scenes. We have a sizeable set of PHP classes, a bunch of perl scripts and a MySQL database, that between them keep track of who all the Utata members are and which photos have been added to which project. The end result of all of this is a pretty smooth and largely automated system. A bunch of cron scripts keep the project database up to date and we have a private administration site that allows Utata administrators to quickly and easily perform a wide variety of tasks: they can set up and publish new projects, create polls, update member details, post new blog entries and so on. We also have HAL, the UtataBot, who keeps a watchful eye on the group pool, making sure that members abide by the rules and that we don’t just become a general dumping ground [RevDanCatt: here’s another pool cleaning bot, hipbot]. There are also the Utata badges that show off the latest contributions to the group pool. Actually, it’s only now, as I sit and write this list, that I realise just how much code there is sitting there on the Utata servers.
One of the key parts of the system is the list of projects and their entries. Utata is a popular site, and it’s clearly not feasible to go back to Flickr to search for project entries each time a page is viewed, so a good deal of the code that runs Utata is devoted to maintaining our local copy of that data – keeping the cached data up to date and retrieving less commonly used elements from Flickr on demand as various pages are viewed. Given the number of projects held on Utata, and the size of the membership, it’s important to make efficient use of the cache, and I’ve tried a number of different strategies to minimise the number of API calls required. The biggest thorn in my side here is the limitation in flickr.photos.search that you can only ever get back the first 4000 photos for a tag-based search. I have some work-arounds to get around that, but if that limitation was ever increased I could make the whole thing far more efficient.
An interesting, but little known fact about Utata, is that it has its own API, which if you were to take a close look at, might well look rather familiar – it uses the Flickr API as its role model. There are only has a limited number of methods right now, but the framework allows more to be added quite easily. The idea behind the API is to enable other interesting applications to be written. There are only a few of these external applications in existence at the moment – there’s a stand-alone project browser, which I don’t think anyone other than me uses. A more interesting one is the Utatascreensaver, which cycles through photos from the Utata project of your choice.
As well as Utata, I dabble with a variety of other projects. The main thing I’m working on right now is a revamp of my Set Manager (http://www.dopiaza.org/flickr/setmgr/). One of the first comments I ever posted to Flickr Ideas was a request for Smart Sets – sets that could dynamically update themselves. You can think of them as the photographic equivalent of SmartPlaylists in iTunes. At the time, I was just starting to experiment with the Flickr API, so I decided to try my hand at building an application to create sets automatically. It’s not especially complicated, it’s really just a simple wrapper around flickr.photos.search, but it has certainly struck a chord with people, with currently over 25,000 authenticated users. It hasn’t changed very much since it was first written, so I figured it was time to give it something of an overhaul.
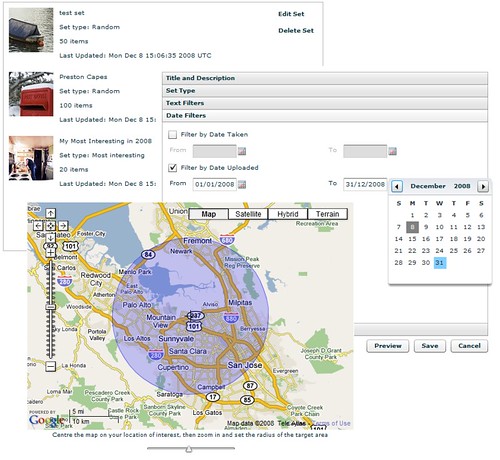
I’ve recently been playing around with Adobe’s Flex framework and decided that revamping the set manager would give me a good excuse to get to learn more about Flex and understand how it all hangs together – and so Version 2 of the set manager is now well under way. This new version allows you to not only build sets based on tags, interestingness, date and so on, it also allows you build sets based around location – the places API provides a very easy way to get access to all of the photos in a given location. For a more visual approach to set building, I’ve also hooked in Google Maps (sorry, Yahoo!) using their rather nifty Flash component to allow areas of interest to be easily chosen. This new Set Manager also piggy-backs on some of the work I did on Utata – it now exposes an API, built using the same framework as the Utata API, to allow the Flex application to communicate with the server.
Most of the Set Manager revamp has now been completed, and few Flickr stalwarts have been helping test it all out. The plan is to get this new version up and running by the end of the year – all I need is a little more spare time to finish things off…
2. What are the best tricks or tips you’ve learned working with the Flickr API?
David: Gustavo sneaked in ahead of me here and got in first with some of the best answers, but the main one is worth repeating – cache your data. Every API call you make can add several seconds on to the run time of your application or the load time of your web page, so you should really think carefully about whether each API call is necessary. If you think you’re going to need that data again in the near future, store it away somewhere – in a database, in the user’s session, anywhere. A good caching strategy can make the difference between a snappy responsive web site and a painfully slow, treacle-laden disaster.
One thing that seems to catch out a lot of people is the 4000 item limit to searches, which seems to be poorly documented (i.e., not at all). If you’re not aware of this limitation, it can suddenly rear it’s ugly head when you’re least expecting it – and usually when it’s least convenient. I remember the first time a Utata tag exceeded 4000 photos (the utatafeature tag currently returns over 16000 photos) and that certainly caused a few headaches. The only solution to this problem seems to be to construct your searches so that they’re sure to return less than 4000 matches. For the Utata tag searches, I ended up breaking the search down into a set of searches using smaller date ranges and aggregated the results. It’s not perfect, but it seems to be holding up.
And if you build an application or tool and release it out into the world, be prepared for an endless stream of emails from people who want it to do something just a little bit different from what it does right now…
3. As a Flickr developer what would you like to see Flickr do more of and why?

David: Well, more Kitten Tuesdays are clearly an obvious priority. Apart from that? Well, here goes:
One of the biggest things I would like to see is a better way for Flickr members to allow API access to their photos. At the moment, users can either opt in or opt out of third-party API searches – it’s an all or nothing thing. There are good reasons for wanting to opt out of searches. It is all too easy, for example, to get an API key and create a rogue application: one that might display photos in an unwelcome context – on a commercial web site, perhaps. Of course, applications that violateFlickr’s terms of service tend to get shut down pretty quickly, but someone has to spot them and bring them to Flickr’s attention before that can happen. Threads regularly appear in the help forum about this, and many people choose to opt-out of public API searches to avoid having their photos show up in places they don’t expect. The problem with opting out is that members can then no longer make use of some of the applications and services that they would actually like to have access to their photos. Utata is a good example – we have many members who would like to take part in the projects but can’t because they are not willing to opt back in to API searches on a global basis.
I would like to see the current opt-out system expanded to allow members who opt out to then opt back in to API searches for selected applications – an API application white list, if you like. That would allow people to explicitly choose which applications were trusted and so grant them access.
There are a few changes to existing API methods that I’d really like to see:
– That 4000 photo limit I keep mentioning – it would be really nice if that could be lifted, even if only for certain search types, such as time-ordered.
– flickr.photos.getInfo returns a whole host of useful information about a photo, but if I want to display that photo somewhere, I also invariably need to know what sizes are available to me. flickr.photos.getSizes gives me that, but that’s now two API calls. I almost always end up calling these two methods as a pair – it would be really nice if flickr.photos.getInfo could optionally return the sizes as well.
– One of the most common feature requests I get for my set manager is the ability to sort by number of favourites, or by views, or by number of comments. Allowing flickr.photos.search to do this would make a lot of people very happy.
– and I know it’s been mentioned quite recently, but searching on EXIF data would be very nice…
4. What excites you about Flick and hacking? What do you think you’ll build next or would like someone else to build so you don’t have to?
David: The thing I love about Flickr is that it’s not just about the photographs. The social network – that jumbled mass of communities that live within Flickr – is really the thing that makes Flickr so compelling. Without those interactions and relationships between people, Flickr would be just another web site full of photos, but as Gustavo’s graphs featured in the last 5 Questions help demonstrate, there’s much more depth to Flickr than a simple on-line photo gallery. It is quite fun building tools to help people perform particular tasks more easily – creating sets, uploading photos, managing group subscription, and so on – but all that’s not a patch the satisfaction gained from building tools that help whole new communities develop. That’s what makes Flickr for me: the people.
What will I build next? I don’t know. There’s always something to tinker with, and you never quite know where that tinkering will lead. The whole shapes thing looks quite interesting, but I haven’t had chance to really have a proper look at that yet. That might well be next on my list to play with – who knows?
5. Besides your own, what Flickr projects and hacks do you use on a regular basis? Who should we interview next?
David: The Flickr tool I’m using the most right now is Jeffrey Friedl’s ‘Export to Flickr’ Lightroom Plug-in (http://regex.info/blog/lightroom-goodies/flickr/). It’s a super little application – it integrates seamlessly with Adobe Lightroom, and does a brilliant job of streamlining the upload process. It’s a very well thought out piece of software – definitely my favourite Flickr tool of 2008.

Who to interview next? Sam Judson (http://www.flickr.com/photos/samjudson/). Sam was technical editor on my Flickr Mashups book (did I forget to mention that I wrote a whole book on building Flickr applications? Flickr Mashups, published by Wrox. Buy one now.). Anyway, as I was saying, Sam was technical editor on my book, and did a great job there, helping point some of my most embarrassing errors before they gotcommitted to print. He knows lots about the API and has been using it for even longer than me. He’s the author of the FlickrNet API library (http://www.codeplex.com/FlickrNet) and a regular contributor to both the Flickr API group and the developer mailing list.
Dan: Thank you, David, and sorry about taking forever to post your answers :) Next up Sam Judson.
Photos by dopiaza, Malingering and Axel Bührmann.