
At Flickr we work with a huge number of photos. Our users upload over 27 million photos a day, and our total collection has over 12 billion photos. This is fantastic! As usage grows, we are always looking for ways to use our storage more efficiently. Recently our storage team wrote about some new commodity storage technology now in use at Flickr which increases efficiency. But we also looked into how much data we store for each photo. In the past we stored many sizes of every photo to make serving fast. We wanted to challenge that model and find the minimal set of data to store.
Thumbnail Footprint Reduction
One of our biggest opportunities for byte per photo improvement is through reduction in the footprint of Flickr’s “thumbnails”. Thumbnail is a bit of a misnomer at Flickr; our thumbnails are as large as 2048 pixels on their longest side, so at Flickr we usually refer to these as resizes. We create these resizes in order to provide a consistent, fast experience for our users over a variety of use cases.

Different sizes used in different contexts. From left to right: Cameraroll uses small thumbnails, to enable fast navigation through many sizes. Our Photo Page uses our largest, most detailed sizes. Search uses sizes in between these two extremes. Red panda photos by Mathias Appel.
The selection of sizes has grown semi-organically over the years, and all told, we serve eleven different resizes per photo which, in sum, use nearly as much storage as the original photo. Almost 90% of this storage is held in the handful of resizes 640px and larger, so we targeted our efforts at eliminating some of these sizes.
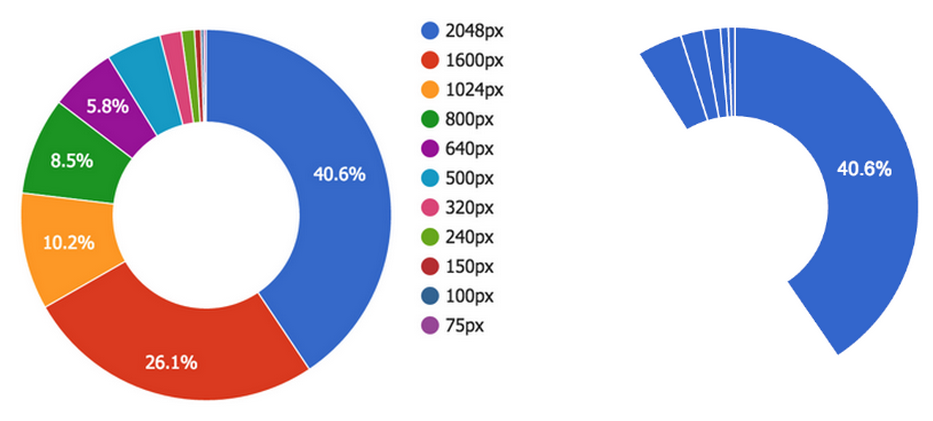
Left: Distribution of byte size by resize dimension. Storage is concentrated in images with largest dimensions. Right: size distribution after largest sizes eliminated.
A Few Approaches
A simple approach to this problem would be just to cease offering some of the larger sizes. For instance, we could drop the 1600px image from our API and require the design to adjust. However, this requires compromises that we didn’t want to take on. Instead we took on a pretty ambitious goal: maintain our largest resize, usually 2048px wide, as a source image and create any other moderate or large-sized resizes on-the-fly from this source, without sacrificing image quality or significantly affecting performance. Using the original uploaded photo as a resize source image was impractical, as these can be very large and exist in a variety of formats.
Sounds easy, right? We already resize images when users upload, so why not just use that same technology on serving. Well, almost. The problem with the naive approach is that high-quality resizing of JPEGs is a lot slower than is widely known. A tool we use frequently, GraphicsMagick, produces beautiful images but takes over 225ms to resize a 2048px JPEG down to 1600px, depending on quality settings. This is slow enough that this method would impact user experience, and would require many CPUs to handle our load. Ymagine, a high-performance CPU-based tool we’ve open sourced, is twice as fast as GraphicsMagick(!). We use Ymagine extensively on smaller images, but for the large sizes we’re targeting we needed even more performance. A GPU-based solution ultimately filled our needs.
Our GPU-based Solution
We created a tier of dedicated resize servers, each with an GPU co-processor. Each of these boards has two GPUs, each with 1500+ “cores”, running at just under 1GHz. These cores aren’t anywhere near as performant as a CPU core, but there are many of them. We tested a range of server-grade boards to find the best performing type for our workload. Many manufacturers offer consumer-grade boards with incredible specifications and lower price points, but these lack server-grade cooling and other features such as ECC RAM. One member of our team had experience using these lower grade boards in a previous application and recommended against it.
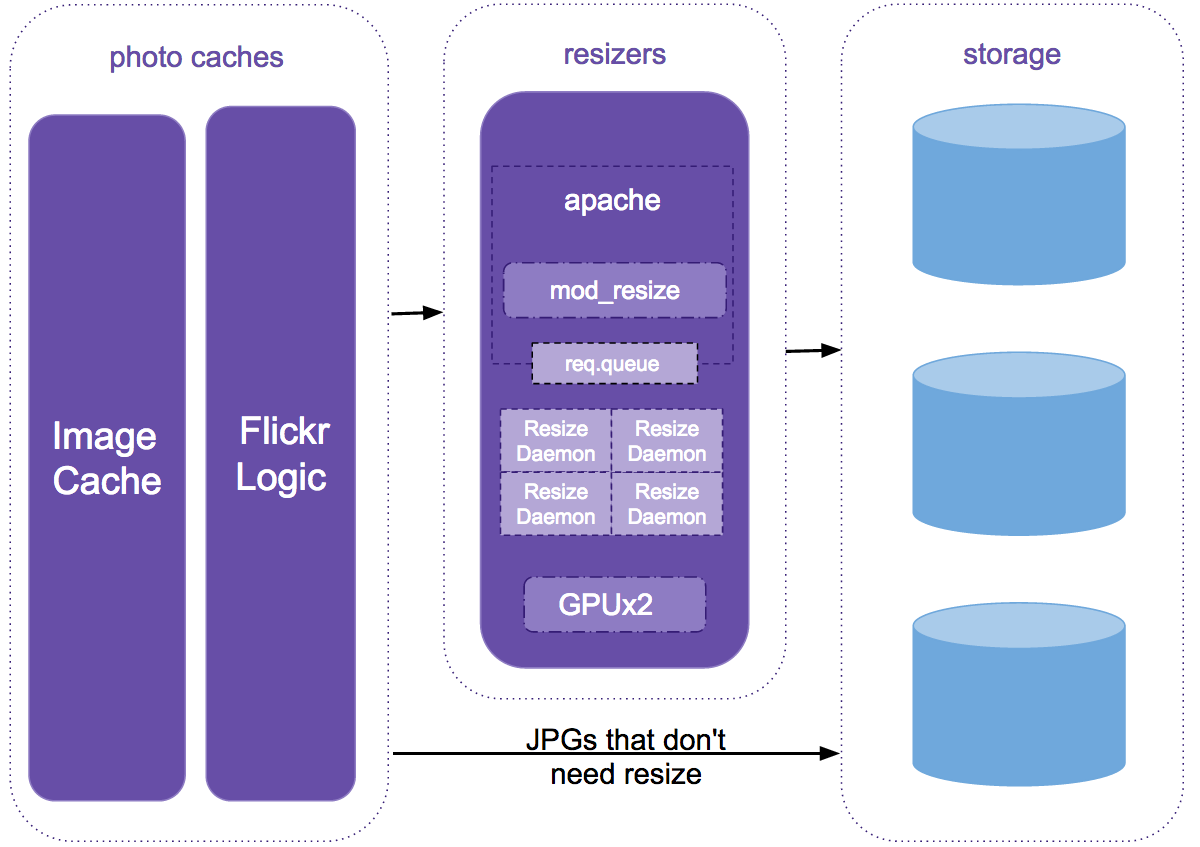
Resize system architecture
On these resize servers we run a fairly vanilla Apache with a plugin written in C++. This server responds to resize requests, reads our source image from disk into shared memory, and hands off requests off to persistent resize daemons that do all communication with our GPUs. A daemon-type approach is necessary due to a somewhat lengthy initialization process with our GPUs.
Our resize daemons transfer JPEGs from shared memory to GPU device memory. Once here, the real image processing takes place. The JPEGs are decoded, cropped, sharpened, resized, re-sharpened as needed, re-encoded as JPEGs, and finally transferred back to shared memory. From shared memory, our Apache module returns the resized JPEG to the caller.
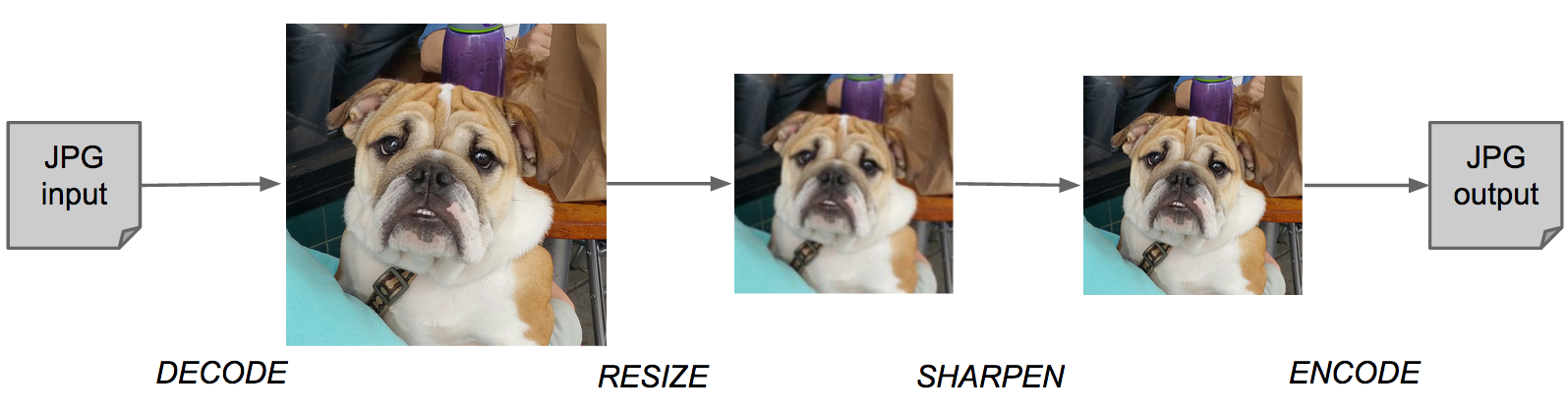
A simple resize pipeline. Post-sharpening overcomes fuzziness introduced when downscaling.
There are several accepted resize algorithms, but to retain the Flickr “look”, we implemented the same Lanczos resize and kernel sharpening algorithms that we’ve used for years in CUDA. This had the added benefit of being able to directly compare images generated through GraphicsMagick and our GPU-based code.
Performance
With significant optimization, this code is able to resize our 2048px JPEGs to 1600px in under 16ms. This is more than 15x faster than GraphicsMagick and nearly 10x faster than Ymagine. Resizes from 2048px to 640px take under 10ms. Equally noteworthy, at peak load, each resize server can perform over 300 resizes per second.
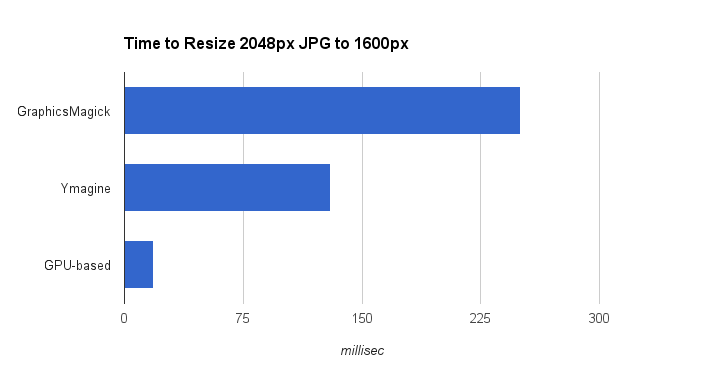
Performance of different resize approaches.
Although these timings are quite fast, the source image for our resizes is larger, byte-wise, than the images it is resizing to, requiring additional I/O. For example, a typical 2048px source JPEG is roughly 600kB and our typical 1024px JPEGs are just under 200kB. This difference in size leads to roughly 35ms additional I/O time per resize.
Taking it slow
As our GPU code is new and images are our most important product, this change carries some risk. We’ve addressed this with extensive testing, progressive rollout and provisions for rollback. We also used some insights into our user behavior to roll this solution out in a very controlled manner.
Conclusion
This system is currently in production and as we roll it out more fully, has the potential to cut the resize footprint of the majority of our photos by 50%, with negligible impact on performance and image appearance. We also have the ability to apply this same footprint reduction technique to images uploaded in the past, which has the potential to reduce our storage growth to zero for a significant period of time.
Credits
This project would not have been possible with hard work of Peter Norby, Tague Griffith, John Ko and many others.