
This past summer we (Yahoo Labs and Flickr) released the YFCC100M dataset that is the largest and most ambitious collection of Flickr photos and videos ever, containing 99,206,564 photos and 793,436 videos from 581,099 different photographers. We’re super excited about the dataset, because it is a reflection of how Flickr and photography have evolved over the past 10 years. And it contains photos and videos of almost everything under the sun (and yes, loads of cats).
We’ve received a lot of emails and tweets asking for more details about the dataset, so in this blog post, we’ll gladly tell you. Each of the 100 million photos and videos is associated with a Creative Commons license that indicates how it may be used by others. The table below shows the complete breakdown of licenses in our dataset. Approximately 31.8% is marked for commercial use, while 17.3% has the most liberal license, which only requires attribution to the photographer.
| License | Photos | Videos |
|---|---|---|
| 17,210,144 | 137,503 | |
| 9,408,154 | 72,116 | |
| 4,910,766 | 37,542 | |
| 12,674,885 | 102,288 | |
| 28,776,835 | 235,319 | |
| 26,225,780 | 208,668 |
The photos and videos themselves are very diverse. We’ve found photos showing street scenes captured as part of photographer Andy Nystrom‘s life-logging activities, photos of real-world events like protests and rallies, as well as photos of natural phenomena.
 |
 |
 |
| Steve Rhodes |
Andy Nystrom |
BJ Graf |
|---|
To understand more about the visual content of the photos in the dataset, the Flickr Vision team used a deep-learning approach to find the presence of visual concepts, such as people, animals, objects, events, architecture, and scenery across a large sample of the corpus. There’s a diverse collection of visual concepts present in the photos and videos, ranging from indoor to outdoor images, faces to food, nature to automobiles.
| Concept | Count |
|---|---|
| outdoor | 32,968,167 |
| indoor | 12,522,140 |
| face | 8,462,783 |
| people | 8,462,783 |
| building | 4,714,916 |
| animal | 3,515,971 |
| nature | 3,281,513 |
| landscape | 3,080,696 |
| tree | 2,885,045 |
| sports | 2,817,425 |
| architecture | 2,539,511 |
| plant | 2,533,575 |
| house | 2,258,396 |
| groupshot | 2,249,707 |
| vehicle | 2,064,329 |
| water | 2,040,048 |
| mountain | 2,017,749 |
| automobile | 1,351,444 |
| car | 1,340,751 |
| food | 1,218,207 |
| concert | 1,174,346 |
| flower | 1,164,607 |
| game | 1,110,219 |
| text | 1,105,763 |
| night | 1,105,296 |
There are 68,971,123 photos and videos in the set that have user-annotated tags. If we look at specific tags used, we see it is very common for people to use the year of capture, the camera brand, place names, scenery, and activities as tags. The top 25 tags (excluding the years of capture) and how often they were used are listed below, as well as the tag frequency distribution for the 100 most-frequently used tags.
| User Tag | Count |
|---|---|
| nikon | 1,195,576 |
| travel | 1,195,467 |
| usa | 1,188,344 |
| canon | 1,101,769 |
| london | 996,166 |
| japan | 932,294 |
| france | 917,578 |
| nature | 872,029 |
| art | 854,669 |
| music | 826,692 |
| europe | 782,932 |
| beach | 758,799 |
| united states | 743,470 |
| england | 739,346 |
| wedding | 728,240 |
| city | 689,518 |
| italy | 688,743 |
| canada | 686,254 |
| new york | 685,311 |
| vacation | 680,142 |
| germany | 672,819 |
| party | 663,968 |
| park | 651,717 |
| people | 641,285 |
| water | 640,234 |
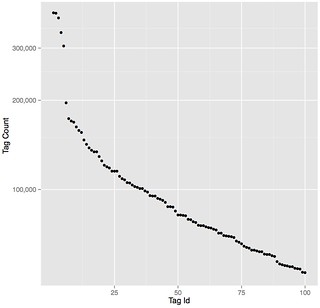
Some photos and videos (3,350,768 to be exact) carry machine tags. Noteworthy machine tags are those having the “siwild” namespace, referring to photos uploaded by scientists of the Smithsonian, and the “taxonomy” namespace, which refers to photos in which flora and fauna have been carefully classified. The most frequently occurring namespace, “uploaded,” refers to the applications used to share the photos on Flickr, which are principally the Flickr and Instagram iOS apps. Other interesting machine tags are those referring to the different filters that can be applied to a photo, or roughly 750,000 photos. Overall, most machine tags are related to food and drink, events, camera and application metadata, as well as locations.
| Machine Tag | Count |
|---|---|
| uploaded | 1,917,650 |
| siwild | 1,169,957 |
| taxonomy | 1,067,857 |
| foursquare | 894,265 |
| exif | 617,287 |
| flickriosapp | 538,829 |
| geo | 443,762 |
| sequence | 429,948 |
| lastfm | 313,379 |
| flickrandroidapp | 222,238 |
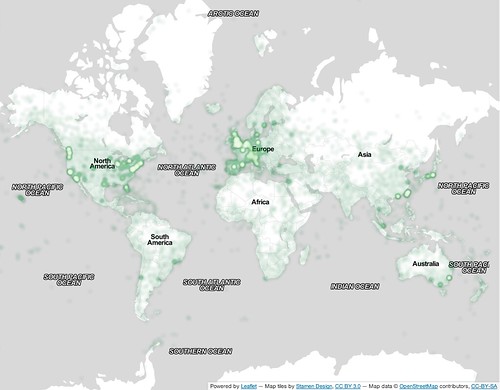
In terms of locations, the photos and videos in the dataset have been taken all over the world. In total, 48,366,323 photos and 103,506 videos were geotagged. The most popular cities where photos and videos were shot are concentrated in the United States, principally New York City, San Francisco, Los Angeles, Chicago, and Seattle; in Europe, they were principally London, Berlin, Barcelona, Rome and Amsterdam. There are also photos that have been taken in remote locations like Kiribati, icy places like Svalbard, and exotic places like Comoros. In fact, photos and videos from this dataset have been taken in 249 different territories (countries, islands, etc) around the world, and even in international waters or airspace.
Our dataset further reveals that there are many different cameras in use within the Flickr community. The Canon EOS 400D and 350D have a lead over the Nikon D90 (calm down…we’re not starting anything by saying that). Apple’s iPhones form the most popular type of cameraphone.
| Make | Camera | Count |
|---|---|---|
| Canon | EOS 400D | 2,539,571 |
| Canon | EOS 350D | 2,140,722 |
| Nikon | D90 | 1,998,637 |
| Canon | EOS 5D Mark II | 1,896,219 |
| Nikon | D80 | 1,719,045 |
| Canon | EOS 7D | 1,526,158 |
| Canon | EOS 450D | 1,509,334 |
| Nikon | D40 | 1,358,791 |
| Canon | EOS 40D | 1,334,891 |
| Canon | EOS 550D | 1,175,229 |
| Nikon | D7000 | 1,068,591 |
| Nikon | D300 | 1,053,745 |
| Nikon | D50 | 1,032,019 |
| Canon | EOS 500D | 1,031,044 |
| Nikon | D700 | 942,806 |
| Apple | iPhone 4 | 922,675 |
| Nikon | D200 | 919,688 |
| Canon | EOS 20D | 843,133 |
| Canon | EOS 50D | 831,570 |
| Canon | EOS 30D | 820,838 |
| Canon | EOS 60D | 772,700 |
| Apple | iPhone 4S | 761,231 |
| Apple | iPhone | 743,735 |
| Nikon | D70 | 742,591 |
| Canon | EOS 5D | 699,381 |
Our collection of 100 million photos and videos marks a new milestone in the history of datasets. The collection is one of the largest released for academic use, and it’s incredibly varied—not just in terms of the content shown in the photos and videos, but also the locations where they were taken, the photographers who took them, the tags that were applied, the cameras that were used, etc. The best thing about the dataset is that it is completely free to download by anyone, given that all photos and videos have a Creative Commons license. Whether you are a researcher, a developer, a hobbyist or just plain curious about online photography, the dataset is the best way to study and explore a wide sample of Flickr photos and videos. Happy researching and happy hacking!
Pingback: Progress up to date | Angelika Szysz - Final Year Project
Pingback: Inside the Creative Commons Dataset from Yahoo and Flickr : Stephen E. Arnold @ Beyond Search
Pingback: Flickr users with the largest number of photos uploaded • djchuang.com