
Norbert Potocki, Software Engineer @ Yahoo Inc.
Warm up: Why configuration management?
When working with large-scale software systems, configuration management becomes crucial; supporting non-uniform environments gets greatly simplified if you decouple code from configuration. While building complex software/products such as Flickr, we had to come up with a simple, yet powerful, way to manage configuration. Popular approaches to solving this problem include using configuration files or having a dedicated configuration service. Our new solution combines the extremely popular GitHub and cfg4j library, giving you a very flexible approach that will work with applications of any size.
Why should I decouple configuration from the code?
- Faster configuration changes (e.g. flipping feature toggles): Configuration can simply be injected without requiring parts of your code to be reloaded and re-executed. Config-only updates tend to be faster than code deployment.
- Different configuration for different environments: Running your app on a laptop or in a test environment requires a different set of settings than production instance.
- Keeping credentials private: If you don’t have a dedicated credential store, it may be convenient to keep credentials as part of configuration. They usually aren’t supposed to be “public,” but the code still may be. Be a good sport and don’t keep credentials in a public GitHub repo. :)
Meet the Gang: Overview of configuration management players
Let’s see what configuration-specific components we’ll be working with today:
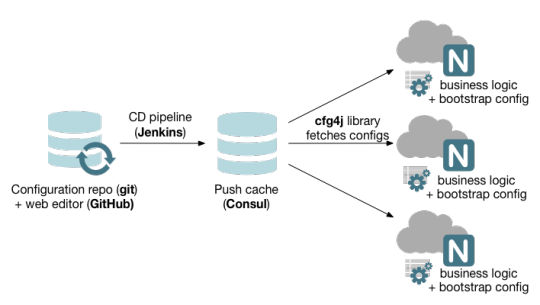
Configuration repository and editor: Where your configuration lives. We’re using Git for storing configuration files and GitHub as an ad hoc editor.
Push cache : Intermediary store that we use to improve fetch speed and to ease load on GitHub servers.
CD pipeline: Continuous deployment pipeline pushing changes from repository to push cache, and validating config correctness.
Configuration library: Fetches configs from push cache and exposing them to your business logic.
Bootstrap configuration : Initial configuration specifying where your push cache is (so that library knows where to get configuration from).
All these players work as a team to provide an end-to-end configuration management solution.
The Coach: Configuration repository and editor
The first thing you might expect from the configuration repository and editor is ease of use. Let’s enumerate what that means:
- Configuration should be easy to read and write.
- It should be straightforward to add a new configuration set.
- You most certainly want to be able to review changes if your team is bigger than one person.
- It’s nice to see a history of changes, especially when you’re trying to fix a bug in the middle of the night.
- Support from popular IDEs – freedom of choice is priceless.
- Multi-tenancy support (optional) is often pragmatic.
So what options are out there that may satisfy those requirements? The three very popular formats for storing configuration are YAML, Java Property files, and XML files. We use YAML – it is widely supported by multiple programming languages and IDEs, and it’s very readable and easy to understand, even by a non-engineer.
We could use a dedicated configuration store; however, the great thing about files is that they can be easily versioned by version control tools like Git, which we decided to use as it’s widely known and proven.
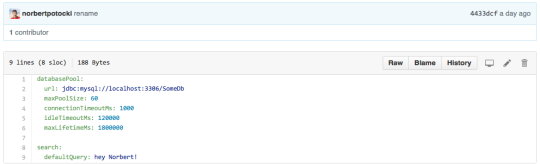
Git provides us with a history of changes and an easy way to branch off configuration. It also has great support in the form of GitHub which we use both as an editor (built-in support for YAML files) and collaboration tool (pull requests, forks, review tool). Both are nicely glued together by following the Git flow branching model. Here’s an example of a configuration file that we use:
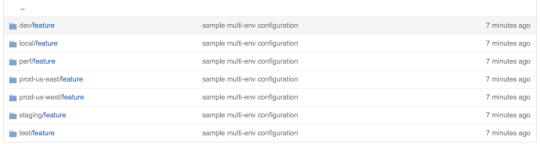
One of the goals was to make managing multiple configuration sets (execution environments) a breeze. We need the ability to add and remove environments quickly. If you look at the screenshot below, you’ll notice a “prod-us-east” directory in the path. For every environment, we store a separate directory with config files in Git. All of them have the exact same structure and only differ in YAML file contents.
This solution makes working with environments simple and comes in very handy during local development or new production fleet rollout (see use cases at the end of this article). Here’s a sample config repo for a project that has only one “feature”:
Some of the products that we work with at Yahoo have a very granular architecture with hundreds of micro-services working together. For scenarios like this, it’s convenient to store configurations for all services in a single repository. It greatly reduces the overhead of maintaining multiple repositories. We support this use case by having multiple top-level directories, each holding configurations for one service only.
The sprinter: Push cache
The main role of push cache is to decrease the load put on the GitHub server and improve configuration fetch time. Since speed is the only concern here, we decided to keep the push cache simple: it’s just a key-value store. Consul was our choice, in part because it’s fully distributed.
You can install Consul clients on the edge nodes and they will keep being synchronized across the fleet. This greatly improves both the reliability and the performance of the system. If performance is not a concern, any key-value store will do. You can skip using push cache altogether and connect directly to Github, which comes in handy during development (see use cases to learn more about this).
The Manager: CD Pipeline
When the configuration repository is updated, a CD pipeline kicks in. This fetches configuration, converts it into a more optimized format, and pushes it to cache. Additionally, the CD pipeline validates the configuration (once at pull-request stage and again after being merged to master) and controls multi-phase deployment by deploying config change to only 20% of production hosts at one time.
The Mascot: Bootstrap configuration
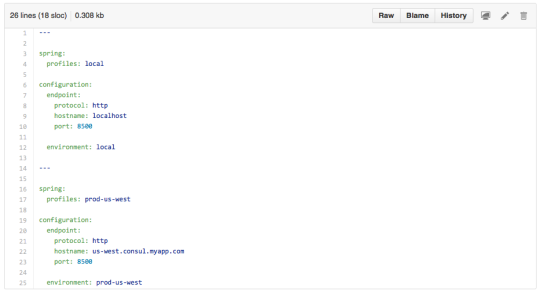
Before we can connect to the push cache to fetch configuration, we need to know where it is. That’s where bootstrap configuration comes into play. It’s very simple. The config contains the hostname, port to connect to, and the name of the environment to use. You need to put this config with your code or as part of the CD pipeline. This simple yaml file binding Spring profiles to different Consul hosts suffices for our needs:
The Cool Guy: Configuration library

The configuration library takes care of fetching the configuration from push cache and exposing it to your business logic. We use the library called cfg4j (“configuration for java”). This library re-loads configurations from the push cache every few seconds and injects them into configuration objects that our code uses. It also takes care of local caching, merging properties from different repositories, and falling back to user-provided defaults when necessary (read more at http://www.cfg4j.org/).
Briefly summarizing how we use cfg4j’s features:
- Configuration auto-reloading: Each service reloads configuration every ~30 seconds and auto re-configures itself.
- Multi-environment support: for our multiple environments (beta, performance, canary, production-us-west, production-us-east, etc.).
- Local caching: Remedies service interruption when the push cache or configuration repository is down and also improves the performance for obtaining configs.
- Fallback and merge strategies: Simplifies local development and provides support for multiple configuration repositories.
- Integration with Dependency Injection containers – because we love DI!
If you want to play with this library yourself, there’s plenty of examples both in its documentation and cfg4j-sample-apps Github repository.
The Heavy Lifter: Configurable code
The most important piece is business logic. To best make use of a configuration service, the business logic has to be able to re-configure itself in runtime. Here are a few rules of thumb and code samples:
- Use dependency injection for injecting configuration. This is how we do it using Spring Framework (see the bootstrap configuration above for host/port values):
https://gist.github.com/norbertpotocki/e91aa64b524592432630
- Use configuration objects to inject configuration instead of providing configuration directly – here’s where the difference is:
Direct configuration injection (won’t reload as config changes)
https://gist.github.com/norbertpotocki/eac0a927ca2df45c2a0b
Configuration injection via “interface binding” (will reload as config changes):
https://gist.github.com/norbertpotocki/0c0b5b9aa9d11c06c937
The exercise: Common use-cases (applying our simple solution)
Configuration during development (local overrides)
When you develop a feature, a main concern is the ability to evolve your code quickly. A full configuration-management pipeline is not conducive to this. We use the following approaches when doing local development:
- Add a temporary configuration file to the project and use cfg4j’s MergeConfigurationSource for reading config both from the configuration store and your file. By making your local file a primary configuration source, you provide an override mechanism. If the property is found in your file, it will be used. If not, cfg4j will fall back to using values from configuration store. Here’s an example (reference examples above to get a complete code):
https://gist.github.com/norbertpotocki/289f3943249ea2813dcf
- Fork the configuration repository, make changes to the fork and use cfg4j’s GitConfigurationSource to access it directly (no push
cache required):
https://gist.github.com/norbertpotocki/dacdcc6671a2158ded5e
- Set up your private push cache, point your service to the cache, and edit values in it directly.
Configuration defaults
When you work with multiple environments, some of them may share a configuration. That’s when using configuration defaults may be convenient. You can do this by creating a “default” environment and using cfg4j’s MergeConfigurationSource for reading config first from the original environment and then (as a fallback) from “default” environment.
Dealing with outages
Configuration repository, push cache, and configuration CD pipeline can experience outages. To minimize the impact of such events, it’s good practice to cache configuration locally (in-memory) after each fetch. cfg4j does that automatically.
Responding to incidents – ultra fast configuration updates (skipping configuration CD pipeline)
Tests can’t always detect all problems. Bugs leak to the production environment and at times it’s important to make a config change as fast as possible to stop the fire. If you’re using push cache, the fastest way to modify config values is to make changes directly within the cache. Consul offers a rich REST API and web ui for updating configuration in the key-value store.
Keeping code and configuration in sync
Verifying that code and configuration are kept in sync happens at the configuration CD pipeline level. One part of the continuous deployment process deploys the code into a temporary execution environment, and points it to the branch that contains the configuration changes. Once the service is up, we execute a batch of functional tests to verify configuration correctness.
The cool down: Summary
The presented solution is the result of work that we put into building huge-scale photo-serving services. We needed a simple, yet flexible, configuration management system. Combining Git, Github, Consul and cfg4j provided a very satisfactory solution that we encourage you to try.
I want to thank the following people for reviewing this article: Bhautik Joshi, Elanna Belanger, Archie Russell.
PS. You can also follow me on Twitter, GitHub, LinkedIn or my private blog.