Introduction
Flickr places a high priority on our users’ experience, and a critical part of that experience is the speed of the interface. Regardless of the client you use to access Flickr, caching the proper data and the speed at which our servers can access cached data is critical to delivering on that quality user experience. The more effective our caching strategy is, the better the Flickr experience will be for our users. This is true for all the layers of caching we deploy at Flickr from the photo caches to the process data caches buried deep in the system. In a previous post, we looked at how regional photo caching improved photo serving time in other countries, in this post we’re going to dive down into the innards of Flickr’s software stack and take a look at how we improved Memcached performance for our backend systems.
Back in the olden days (pre-2014), we accessed our Memcached systems through a mix of direct reads from our web servers and writes through a Flickr-developed proxy. Our proprietary proxy system, Cerberus, handled a whole host of responsibilities. In addition to Memcached set operations, Cerberus managed database updates, the bulk of our Redis accesses, cache consistency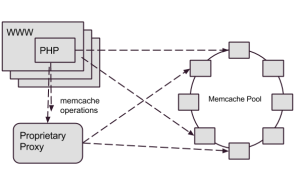 (which is why we directed our writes through Cerberus), and a few other miscellaneous transactions. As Flickr’s traffic and functionality had grown, Memcached set operation performance wasn’t keeping up, so we needed to consider how to address the gap.
(which is why we directed our writes through Cerberus), and a few other miscellaneous transactions. As Flickr’s traffic and functionality had grown, Memcached set operation performance wasn’t keeping up, so we needed to consider how to address the gap.
Since the development of Cerberus, the software landscape had drastically changed. When we developed Cerberus, there was no comparable software available, but now several open source projects exist that provide similar proxy services. On top of the availability of open source tools, Flickr’s traffic and usage patterns have changed over the course of a decade, changing the requirements we had for a proxy system. Needless to say we had a lot of questions to ask ourselves before we dived into revising the caching architecture.
After years of operation, we had a good picture into the strengths and weaknesses of our current architecture, so when we started thinking about revising it, a few lessons from the past years really stood out. One thing that we learned over the years was that Cerberus’ lack of a single purpose made it difficult to troubleshoot operational issues with Memcached. Due to the lack of isolation, a downstream issue with a user database, could impact Memcached access time. Whatever came next had to isolate cache requests from other data accesses.
Experience had shown us that Memcached get operation latency was a key performance metric, and we learned through trial and error that placing our current Cerberus proxy between the web servers and the Memcached hosts added more network latency than we were willing to tolerate. Unfortunately, our options for connection pooling and more efficient use of connections were limited in PHP, so we had little recourse than to suffer with a high connection load and fluctuating connections against our Memcached servers. The next generation system would have to carefully monitor get operation timings and ensure we didn’t introduce more latency into the process.
So as 2014 rolled around, we started to look into an alternative to Cerberus for accessing the Memcached systems. Should we build a Cerberus 2.0? Should we look at an open source alternative? As we weighed our options, one alternative that stood out because it was quite successful in other parts of Yahoo and throughout the industry was Twitter’s Twemproxy.
Introducing Twemproxy
Twemproxy is a lightweight daemon that proxies requests to a pool of Memcached instances. It provides the following features that we believed would improve our caching infrastructure:
- Consistent hashing: Figuring out what hosts in the ring on which to store and retrieve cache data. While we had implemented consistent hashing before Twemproxy, it was previously left to the client libraries to sort out.
- Connection pooling: Reuse of network connections to the Memcached instances, cutting down significantly on the connection load to the Memcached daemons.
- Command Pipelining: Accumulating requests destined for the same host and sending as a combined payload. This feature further reduces connection load and network overhead to the cache processes.
Resulting Architecture
We implemented a solution where each web server host had two local Twemproxies, forwarding to the Memcached rings.
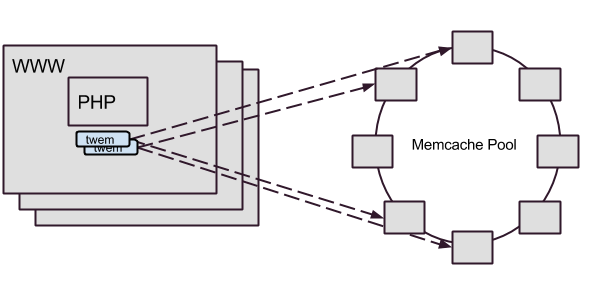
In the resulting architecture, all Memcached operations go through twemproxy. The change accomplished many goals, including:
- Providing a dedicated system for Memcached requests that was isolated from other systems
- Reducing the connection load on our Memcached servers through Twemproxy’s connection pooling. We experienced a 75% overall reduction of TCP connections to Memcached nodes
- Improved overall caching latency. This was a benefit that we didn’t necessarily expect. With Twemproxy, we found that get operations had a 5% reduction in mean processing time and set operations had a 40% in mean processing time
The Road to Twemproxy
As nice as it would be to say we dropped in Twemproxy, declared victory and went for ice cream, we still had to solve a few interesting challenges along the way: maintaining availability, dealing with disparate consistent hashing schemes, and re-implementing cache coherency.
If One is Good, Two is Even Better
From the start, we recognized that the simple daemon model of Twemproxy would need to be managed carefully. Each deploy through our continuous deployment system could result in changes to the Memcached hosts configuration. And unfortunately, configuration changes for Twemproxy require the process to be restarted to take effect. We measured the time to restart Twemproxy in the 1-2 second range, but even for these necessary restarts, it was too much of an interruption for the clients.
Our solution was to run two instances of the daemon on every host that needed the service and manage a careful synchronization between the restarts. This restart “dance” was wired into the process that deploys the configuration changes to all the Memcached clients. A couple of patches have been proposed to allow configuring Twemproxy without restarting it, but none of them have yet made the master branch.
When is Ketama not Ketama?
Ketama is a popular consistent hashing algorithm used by many systems to determine where to place a particular key in a multi-node caching system. Out of the box, Twemproxy uses an implementation of the Ketama algorithm that is compatible with libketama, the C library which is the most commonly used implementation of the Ketama algorithm.
Our initial implementation of consistent hashing was done using Ketama, but with the Spymemcached Java library. It turns out that Spymemcached has a slight variation in the implementation that makes it incompatible with Twemproxy.
Our transition from our current system to Twemproxy had to happen live, and a sudden change in the cache algorithm would have a painful (and unacceptable) impact on our database systems. How could we get across this bridge? Ultimately, we had to patch Twemproxy’s implementation of Ketama to match Spymemcached to maintain a consistent implementation of the Ketama algorithm.
Redis latency in propagating cache clears
Until we figure out how to change the speed of light, the only way we are going to make Flickr fast across the world, is through multiple data centers conveniently located near our users. While this is way easier than changing the speed of light, it’s not without its complications.

Caches between the data centers have to be kept consistent. Some caches, like photo caches, deal with immutable data and are easy to keep in synch, others like Memcached systems have read-write data which is harder. Our approach to handling cache consistency in our Memcached systems was to invalidate stale keys in other colo facilities whenever a process updated a value. As we mentioned previously, Memcache write operations were directly through our Cerberus proxy specifically so Cerberus could dispatch a cache invalidation event to other colo facilities. The migration to Twemproxy would not be complete, until we implemented a new solution for cache invalidation.
In our Twemproxy-based architecture, we decided to take the responsibility for cache invalidation our of the hands of the data proxy and push it into the client libraries we used to access Memcached. Whenever a client updates a Memcache key, it enqueues a corresponding cache invalidation event into a distributed Redis queue. We then deployed simple, single-purpose Java daemons to process the cache invalidation events from the Redis queue and delete the corresponding keys in their local Memcached systems. A diagram of the system, appears below: 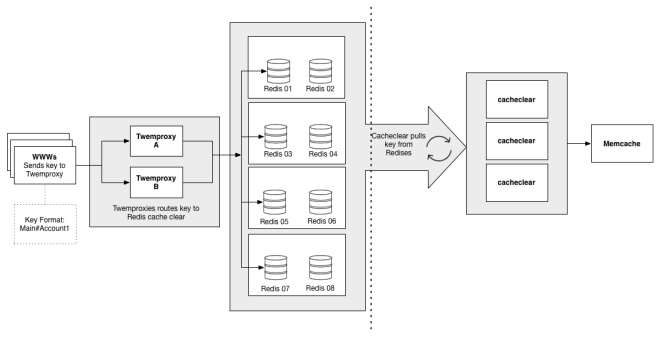
The wrinkle with this approach was that the enqueuing of clear keys would occasionally take 20 times longer than the normal mean time, pushing cache sets up to 40ms. After much digging, we found that the spikes were happening when the clearing daemons dequeued a batch of keys. The dequeuing daemons were performing operations across a WAN. Due to the single-threaded nature of Redis, it would periodically block the queue for adding keys for 10s of milliseconds. Once we figured that out, the fix was a matter of keeping separate in- and out-queues, and moving the keys from in to out with a local daemon, which significantly reduced the blocked time for writing keys.
Conclusion
Caching is crucial to a high-traffic site like Flickr, and we have taken a big stride in making our Memcached utilization more effective. Using Twemproxy, we were able to clean up an internal system, reduce the connection load on our caching daemons, and even make modest improvements to caching latency for all clients. Although we faced some technical challenges in implementing twemproxy for Memcached, particularly in propagating cache clear events, it was ultimately well worth the engineering investment. After several months, our implementation of Twemproxy has proven to make a positive contribution to caching speed and ultimately the experience of a responsive site for our users.
If you dream in low latency and love to rip that extra 10 microseconds of overhead out of an operation, we’d love to have you! Stop by our Jobs page and tell us how awesome you are.