|
OR |  |
Zion National Park Utah by Les Haines  |
Secretary Bird by Bill Gracey  |
tl;dr: Check it out at parkorbird.flickr.com!
We at Flickr are not ones to back down from a challenge. Especially when that challenge comes in webcomic form. And especially when that webcomic is xkcd. So, when we saw this xkcd comic we thought, “we’ve got to do that”:
 |
 |
In fact, we already had the technology in place to do these things. Like the woman in the comic says, determining whether a photo with GPS info embedded into it was taken in a national park is pretty straightforward. And, the Flickr Vision team has been working for the last year or so to be able to recognize more than 1000 things in images using deep convolutional neural nets. Incidentally, one of the things we’re pretty good at recognizing is birds!
We put those things together, and thus was born parkorbird.flickr.com!
Recognizing Stuff in Images with Deep Networks
The thing we’re really excited to show off with PARK or BIRD is our image recognition technology. To recognize 1000+ things, we employ a deep convolutional neural network similar to the one depicted below.
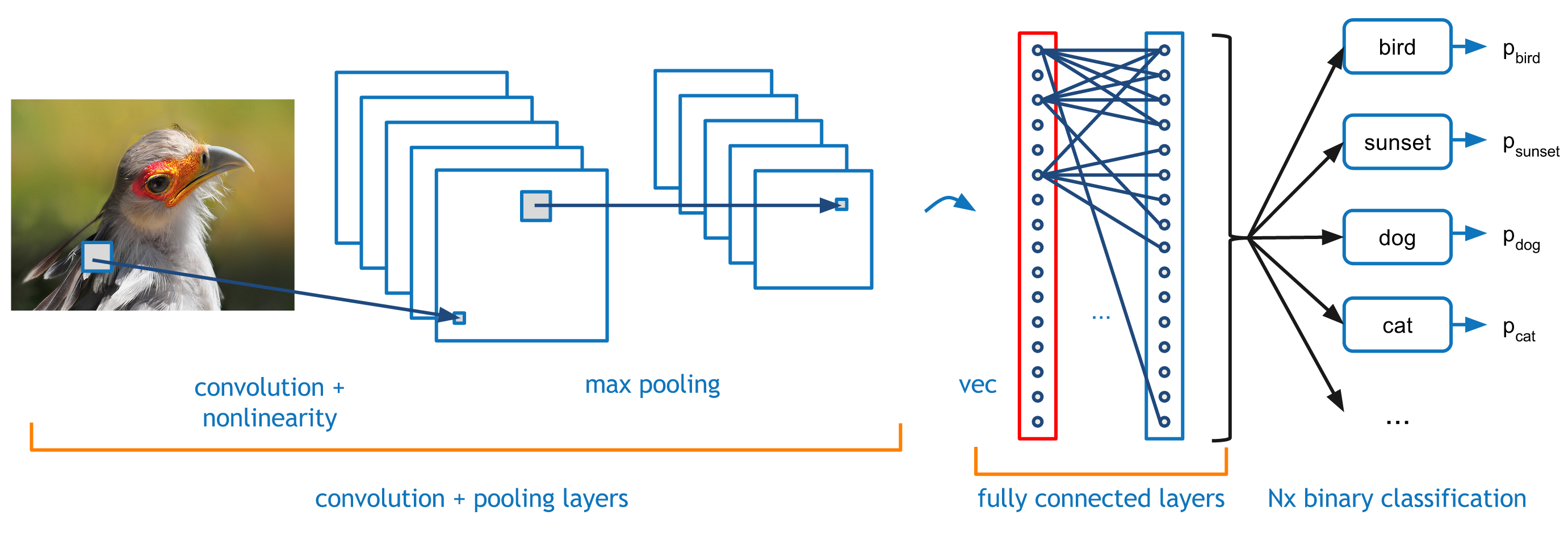
This model transforms an input image into a representation in which different objects and scenes are easily distinguishable by a simple binary classification algorithm, like an SVM. It does this by passing the image through a series of layers, where each layer computes a function of the output of the layer below it.
Each successive one of these layers, after training on millions of images, has learned to recognize higher- and higher-level features of images and the ways these features go together to form different objects and scenes. For example, the first layer might recognize the most basic image features, such as short straight lines, corners, and small circular arcs. The next layer might recognize higher level combinations of those features, such as circles or other basic shapes. Further layers might recognize higher-level concepts, like eyes and beaks, and even further ones might recognize heads and wings. For an example of what this looks like, check out Figure 2 in this paper by Matt Zeiler and Rob Fergus.
As the image passes through these layers, they are “activated” in different ways depending on the features they’ve seen in the input image, and at the top of this network—after the image is transformed by the bottom layer, and that transformation of the image is transformed by the next layer, and that transformation of the transformation of the image is transformed by the next layer, and so on— a short floating-point vector summarizing all of the various activations at each layer is output. We pass this floating-point vector into more than 1000 binary classifiers, each of which is trained to give us a yes/no answer to identify a specific object/scene class. And, of course, one of those classes is birds!
The Flickr Vision team is already applying this deep network to Flickr photos to help people more more easily find what they’re looking for via Flickr search, and we plan to integrate it into Flickr in other cool ways in the future. We’re also working on other innovative computer vision and image recognition technologies that will make it easier for Flickr members to find and organize their photos.
Acknowledgements
The Flickr Vision and Search team is awesome and PARK or BIRD is built upon technologies that we all pitched in on. Here we all are (at least most of us), in all our beautiful glory. Thanks Vision/Search! Thanks also to Stephen Woods, Bart Thomee, John Ko, Mike Shema, and Sean Perkins, all of whom provided a lot of help getting PARK or BIRD off the ground.

If this all sounds like a challenge you’re interested in helping out with, you should join us! Flickr is hiring engineers, designers and product managers in our San Francisco office. Find out more at flickr.com/jobs.