A long long time ago (2005) in a galaxy far far way (Vancouver) when we joined Yahoo! and moved FlickrHQ to the Bay Area all but one or two members of the team lived within ten square blocks of each other in San Francisco’s Mission District.
John Allspaw, a long-time resident of the Mission used to regale us with stories of one of the neighbourhood’s notable quirks commonly referred to as the “donut hole”: The rest of the city could be covered in fog, or raining, but the moment you crossed over in the Mission the sky would open up and the entire neighbourhood would be bathed in sunshine.
When John and George Oates and I used to car pool between the city and the offices in Sunnyvale, we would drive up and down highway 280 and sure enough as you approached the city, at the end of the day, you would drive into an enormous blanket of fog the moment we passed the airport in Millbrae. And as soon as we’d pulled off the San Jose exit there would be an open stretch of clear sky all the way to Civic Center where it would stop again just as suddenly.
Some mornings, when I look out my kitchen window at the clouds hanging over Diamond Heights I like to pretend I can see the curvature of the inside of the donut hole itself. I was reminded of all this the other morning when I was generating some visualizations based on the shapefiles that are derived from the almost 100 million geotagged photos on Flickr.

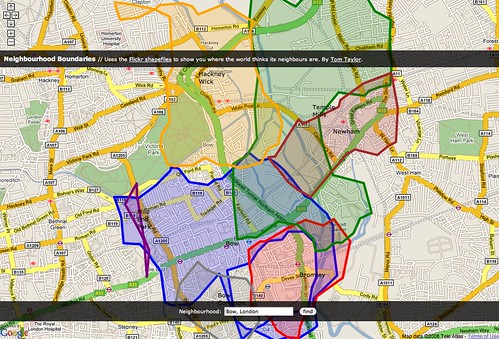
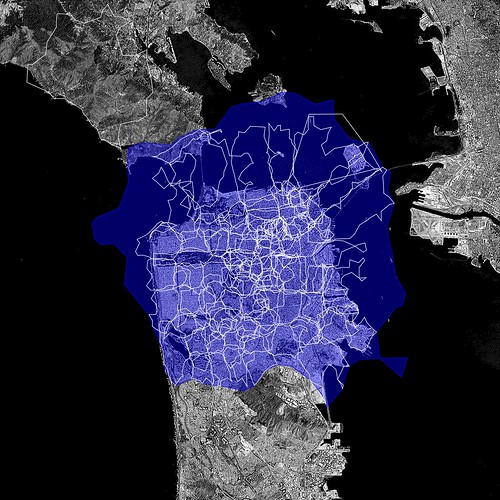
The larger, blue, contour is the “shape” of the city of Paris (or WOE ID 615702) according to Flickr. The smaller white contours are the child neighbourhoods of that WOE ID with public, geotagged photos. So, what’s going on then?
The first outline maps roughly to the extremities of the RER, the communter train that services Paris and the surrounding suburbs. This is a fairly accurate representation of the “greater metropolitain” area of Paris. Metropolitain areas, increasingly common in both popular folklore and government administrivia as more and more people shift from rural to urban living , are noticeably lacking from the Flickr hierarchy of place types and a subject probably best left for another blog post.

The rest, taken as a whole, follow closer to the shape of the old city gates that most people think of when asked to imagine Paris. Which one is right? Well, both obviously!
Cities long ago stopped being defined by the walls that surround(ed) them. There is probably no better place in the world to see this than Barcelona which first burst out of its Old City with the construction of the Eixample at the end of the 19th century and then again, after the wars, pushed further out towards the hills and rivers that surround it.
There are lots of reasons to criticize urban sprawl as a phenomenon but sprawl, too, is still made of people who over time inherit, share and shape the history and geography they live in. Whether it’s Paris, Los Angeles, William Gibson’s dystopic “Boston-Atlanta Metropolitain Axis” (BAMA) or the San Francisco “Bay Area” they all encompass wildly different communities who, in spite of the grievances harboured towards one another, often feel as much of a connection to the larger whole as they do to whatever neighbourhood, suburb or village they spend their days and nights in.

That’s one reason I think it’s so interesting to look at the shape of cities and see how they spill out beyond the boundaries of traditional maps and travel guides. In the example above the shape for Paris completely engulfs the commune of Orly, 20 kilometers to the South of central Paris, which makes a certain amount of sense.
It also contains Orly airport which isn’t that notable except that we treat airports as though they were cities in their own right because the realities of contemporary travel mean that airports have evolved from being simple gateways to captial-P places with their own culture, norms and gravity. So, now you have cities contained within cities which most people would tell you are just neighbourhoods.
We’re recently finished rendering the second batch of shapefiles and looking ahead I am wondering whether we should also be rendering shapes based on the relationship of one place to another. Rendering the shape of the child places for a city or a country (you can do this using the handy, if awkwardly named, flickr.places.getChildrenWithPhotosPublic API method) would allow you to see a city’s “center” but also provide a way to filter out parts of a shape with low Earthiness (aka water).
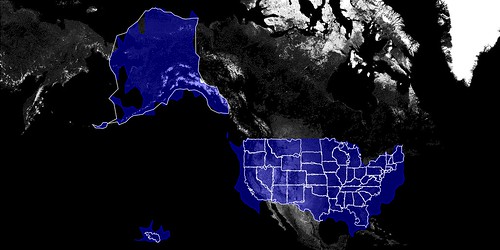
The issue is not to prevent, or correct, shapes that provide a “false” view because I don’t think they do. As Schuyler observed, while we were getting all this stuff to work in the first place, and testing the neighbourhoods that meet San Francisco Bay they are really the shapes of people looking at the city. They are each different, but the same.
But maybe we should also map the neighbourhoods that aren’t considered the immediate children of a city but which overlap its boundaries. What if you could call an API method to return the list or the shape of a place’s “cousins”? What could that tell us about a place?
What does all of this have to do with donuts? Nothing really, but it’s a nice way to think about the problem and since we have a long and storied tradition of silly names for projects I imagine this one will stick too.
There are no fixed dates yet for when, or whether, any of this will make its way in to the API but quite a lot of it could be done with API methods already available today. One change we have made is to add a new flickr.places.getShapeHistory API method which include pointers to all the shapefiles that have been rendered for a place. I have dim and distant memories of possible reasons why not to do this, in the past, but the exercise in making donut shapes makes me think I was wrong. The more data and “nubby bits” that people have to work with the more interesting it will be for everyone.
Enjoy!