
There are two primary paradigms for the discovery of digital content. First is the search paradigm, in which the user is actively looking for specific content using search terms and filters (e.g., Google web search, Flickr image search, Yelp restaurant search, etc.). Second is a passive approach, in which the user browses content presented to them (e.g., NYTimes news, Flickr Explore, and Twitter trending topics). Personalization benefits both approaches by providing relevant content that is tailored to users’ tastes (e.g., Google News, Netflix homepage, LinkedIn job search, etc.). We believe personalization can improve the user experience at Flickr by guiding both new as well as more experienced members as they explore photography. Today, we’re excited to bring you personalized group recommendations.
Flickr Groups are great for bringing people together around a common theme, be it a style of photography, camera, place, event, topic, or just some fun. Community members join for several reasons—to consume photos, to get feedback, to play games, to get more views, or to start a discussion about photos, cameras, life or the universe. We see value in connecting people with appropriate groups based on their interests. Hence, we decided to start the personalization journey by providing contextually relevant and personalized content that is tuned to each person’s unique taste.
Of course, in order to respect users’ privacy, group recommendations only consider public photos and public groups. Additionally, recommendations are private to the user. In other words, nobody else sees what is recommended to an individual.
In this post we describe how we are improving Flickr’s group recommendations. In particular, we describe how we are replacing a curated, non-personalized, static list of groups with a dynamic group recommendation engine that automatically generates new results based on user interactions to provide personalized recommendations unique to each person. The algorithms and backend systems we are building are broad and applicable to other scenarios, such as photo recommendations, contact recommendations, content discovery, etc.
Figure: Personalized group recommendations
Challenges
One challenge of recommendations is determining a user’s interests. These interests could be user-specified, explicit preferences or could be inferred implicitly from their actions, supported by user feedback. For example:
- Explicit:
- Ask users what topics interest them
- Ask users why they joined a particular group
- Implicit:
- Infer user tastes from groups they join, photos they like, and users they follow
- Infer why users joined a particular group based on their activity, interactions, and dwell time
- Feedback:
- Get feedback on recommended items when users perform actions such as “Join” or “Follow” or click “Not interested”
Another challenge of recommendations is figuring out group characteristics. I.e.: what type of group is it? What interests does it serve? What brings Flickr members to this group? We can infer this by analyzing group members, photos posted to the group, discussions and amount of activity in the group.
Once we have figured out user preferences and group characteristics, recommendations essentially becomes a matchmaking process. At a high-level, we want to support 3 use cases:
- Use Case # 1: Given a group, return all groups that are “similar”
- Use Case # 2: Given a user, return a list of recommended groups
- Use Case # 3: Given a photo, return a list of groups that the photo could belong to
Collaborative Filtering
One approach to recommender systems is presenting similar content in the current context of actions. For example, Amazon’s “Customers who bought this item also bought” or LinkedIn’s “People also viewed.” Item-based collaborative filtering can be used for computing similar items.

Figure: Collaborative filtering in action
By Moshanin (Own work) [CC BY-SA 3.0] from Wikipedia
Intuitively, two groups are similar if they have the same content or same set of users. We observed that users often post the same photo to multiple groups. So, to begin, we compute group similarity based on a photo’s presence in multiple groups.
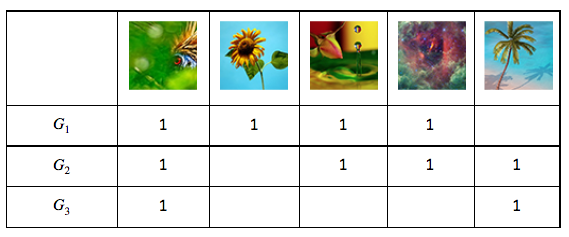
Consider the following sample matrix M(Gi -> Pj) constructed from group photo pools, where 1 means a corresponding group (Gi) contains an image, and empty (0) means a group does not contain the image.
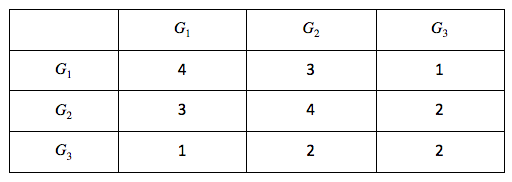
From this, we can compute M.M’ (M’s transpose), which gives us the number of common photos between every pair of groups (Gi, Gj):
We use modified cosine similarity to compute a similarity score between every pair of groups:
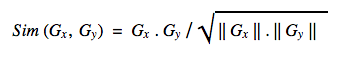
To make this calculation robust, we only consider groups that have a minimum of X photos and keep only strong relationships (i.e., groups that have at least Y common photos). Finally, we use the similarity scores to come up with the top k-nearest neighbors for each group.
We also compute group similarity based on group membership —i.e., by defining group-user relationship (Gi -> Uj) matrix. It is interesting to note that the results obtained from this relationship are very different compared to (Gi, Pj) matrix. The group-photo relationship tends to capture groups that are similar by content (e.g.,“macro photography”). On the other hand, the group-user relationship gives us groups that the same users have joined but are possibly about very different topics, thus providing us with a diversity of results. We can extend this approach by computing group similarity using other features and relationships (e.g., autotags of photos to cluster groups by themes, geotags of photos to cluster groups by place, frequency of discussion to cluster groups by interaction model, etc.).
Using this we can easily come up with a list of similar groups (Use Case # 1). We can either merge the results obtained by different similarity relationships into a single result set, or keep them separate to power features like “Other groups similar to this group” and “People who joined this group also joined.”
We can also use the same data for recommending groups to users (Use Case # 2). We can look at all the groups that the user has already joined and recommend groups similar to those.
To come up with a list of relevant groups for a photo (Use Case # 3), we can compute photo similarity either by using a similar approach as above or by using Flickr computer vision models for finding photos similar to the query photo. A simple approach would then be to recommend groups that these similar photos belong to.
Implementation
Due to the massive scale (millions of users x 100k groups) of data, we used Yahoo’s Hadoop Stack to implement the collaborative filtering algorithm. We exploited sparsity of entity-item relationship matrices to come up with a more efficient model of computation and used several optimizations for computational efficiency. We only need to compute the similarity model once every 7 days, since signals change slowly.
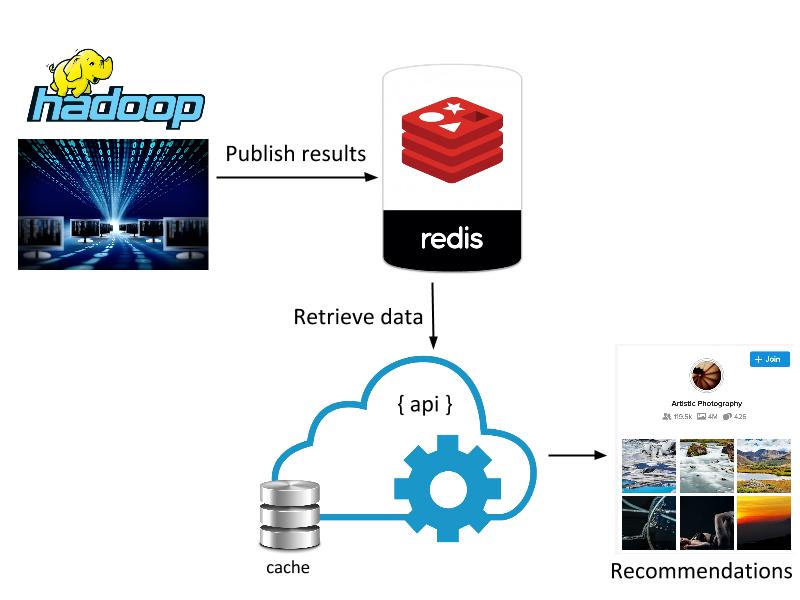
Figure: Computational architecture
(All logos and icons are trademarks of respective entities)
Similarity scores and top k-nearest neighbors for each group are published to Redis for quick lookups needed by the serving layer. Recommendations for each user are computed in real-time when the user visits the groups page. Implementation of the serving layer takes care of a few aspects that are important from usability and performance point-of-view:
- Freshness of results: Users hate to see the same results being offered even though they might be relevant. We have implemented a randomization scheme that returns fresh results every X hours, while making sure that results stay static over a user’s single session.
- Diversity of results: Diversity of results in recommendations is very important since a user might not want to join a group that is very similar to a group he’s already involved in. We require a good threshold that balances similarity and diversity. To improve diversity further, we combine recommendations from different algorithms. We also cluster the user’s groups into diverse sets before computing recommendations.
- Dynamic results: Users expect their interactions to have a quick effect on recommendations. We thus incorporate user interactions while making subsequent recommendations so that the system feels dynamic.
- Performance: Recommendation results are cached so that API response is quick on subsequent visits.
Cold Start
The drawback to collaborative filtering is that it cannot offer recommendations to new users who do not have any associations. For these users, we plan to recommend groups from an algorithmically computed list of top/trending groups alongside manual curation. As users interact with the system by joining groups, the recommendations become more personalized.
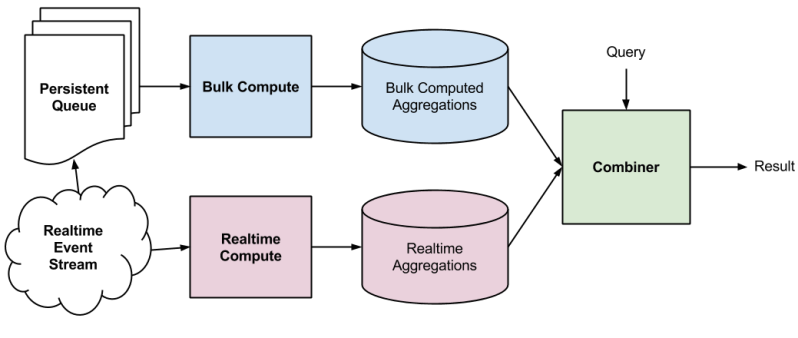
Measuring Effectiveness
We use qualitative feedback from user studies and alpha group testing to understand user expectation and to guide initial feature design. However, for continued algorithmic improvements, we need an objective quantitative metric. Recommendation results by their very nature are subjective, so measuring effectiveness is tricky. The usual approach taken is to roll out to a random population of users and measure the outcome of interest for the test group as compared to the control group (ref: A/B testing).
We plan to employ this technique and measure user interaction and engagement to keep improving the recommendation algorithms. Additionally, we plan to measure explicit signals such as when users click “Not interested.” This feedback will also be used to fine-tune future recommendations for users.
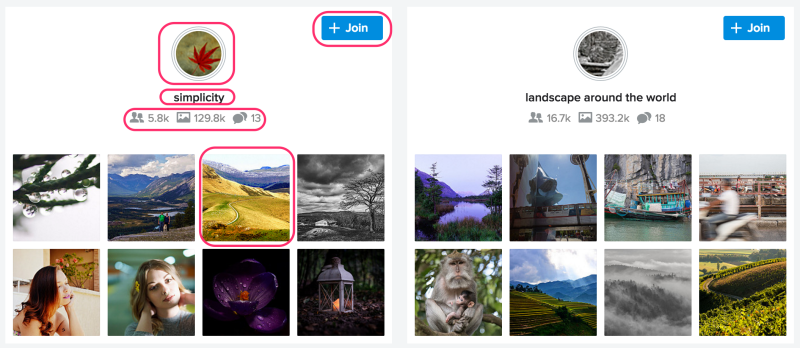
Figure: Measuring user engagement
Future Directions
While we’re seeing good initial results, we’d like to continue improving the algorithms to provide better results to the Flickr community. Potential future directions can be classified broadly into 3 buckets: algorithmic improvements, new product use cases, and new recommendation applications.
If you’d like to help, we’re hiring. Check out our jobs page and get in touch.
Product Engineering: Mehul Patel, Chenfan (Frank) Sun, Chinmay Kini
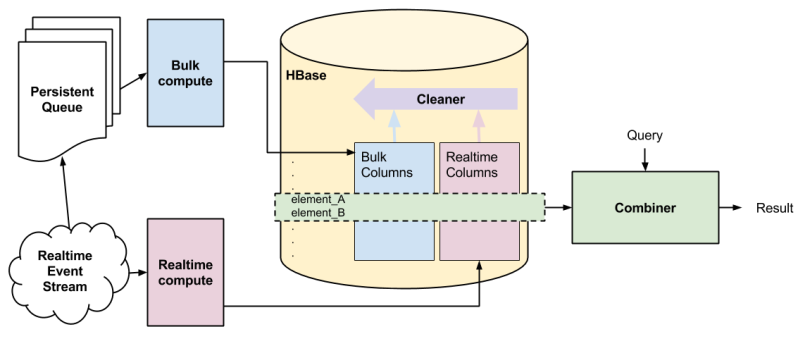

 (which is why we directed our writes through Cerberus), and a few other miscellaneous transactions. As Flickr’s traffic and functionality had grown, Memcached set operation performance wasn’t keeping up, so we needed to consider how to address the gap.
(which is why we directed our writes through Cerberus), and a few other miscellaneous transactions. As Flickr’s traffic and functionality had grown, Memcached set operation performance wasn’t keeping up, so we needed to consider how to address the gap.

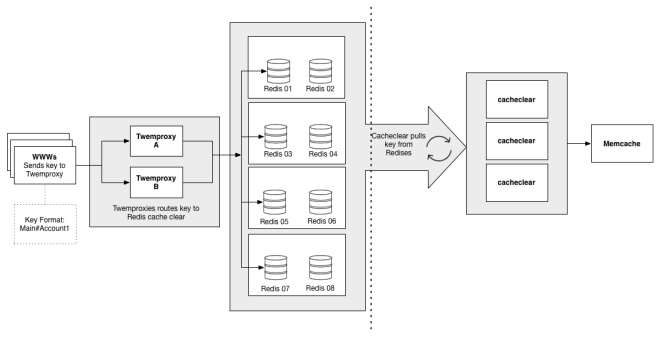
{kind=link}