The name sort of says it all, really, but here’s the short version:
We are releasing all of the Flickr shapefiles as a single download, available for use under the Creative Commons Zero Waiver. That’s fancy-talk for “public domain”.
The long version is:
To the extent possible under law, Flickr has waived all copyright and related or neighboring rights to the “Flickr Shapefiles Public Dataset, Version 1.0”. This work is published from the United States. While you are under no obligation to do so, wherever possible it would be extra-super-duper-awesome if you would attribute flickr.com when using the dataset. Thanks!
We are doing this for a few reasons.
- We want people (developers, researchers and anyone else who wants to play) to find new and interesting ways to use the shapefiles and we recognize that, in many cases, this means having access to the entire dataset.
- We want people to feel both comfortable and confident using this data in their projects and so we opted for a public domain license so no one would have to spend their time wondering about the issue of licensing. We also think the work that the Creative Commons crew is doing is valuable and important and so we chose to release the shapefiles under the CC0 waiver as a show of support.
- We want people to create their own shapefiles and to share them so that other people (including us!) can find interesting ways to use them. We’re pretty sure there’s something to this “shapefile stuff” even if we can’t always put our finger on it so if publishing the dataset will encourage others to do the same then we’re happy to do so.

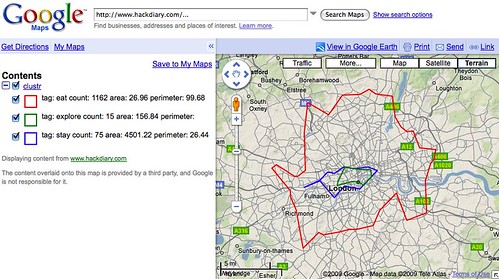
The dataset itself is pretty straightforward. It is a single 549MB XML file uncompressed (84MB when zipped). The data model is a simple, pared-down version of what you can already get via the Flickr API with an emphasis on the shape data.
Everything lives under a single root places element. For example:
<place woe_id="26" place_id="BvYpo7abBw" place_type="locality" place_type_id="7" label="Arvida, Quebec, Canada"> <shape created="1226804891" alpha="0.00015" points="45" edges="15" is_donuthole="0"> <polylines bbox="48.399932861328,-71.214576721191,48.444801330566,-71.157333374023"> <polyline> <!-- points go here--> </polyline> </polylines> <shapefile url="http://farm4.static.flickr.com/3203/shapefiles/26_20081116_082a565562.tar.gz" /> </shape> <!-- and so on --> </place>
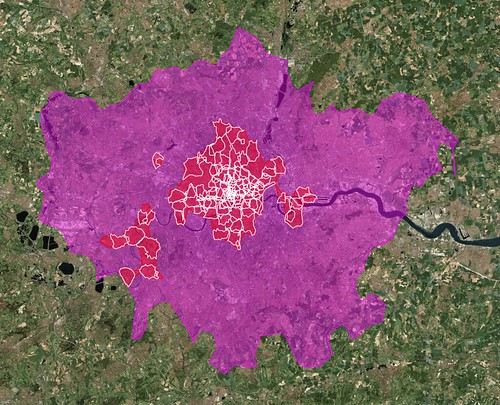
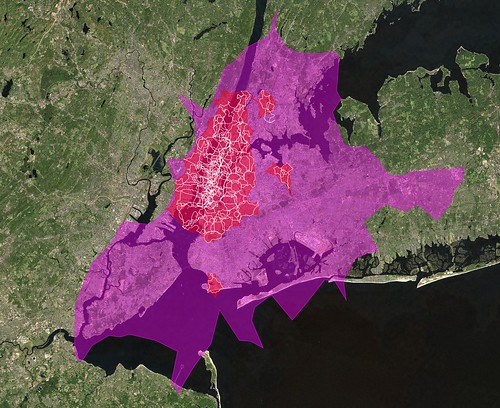
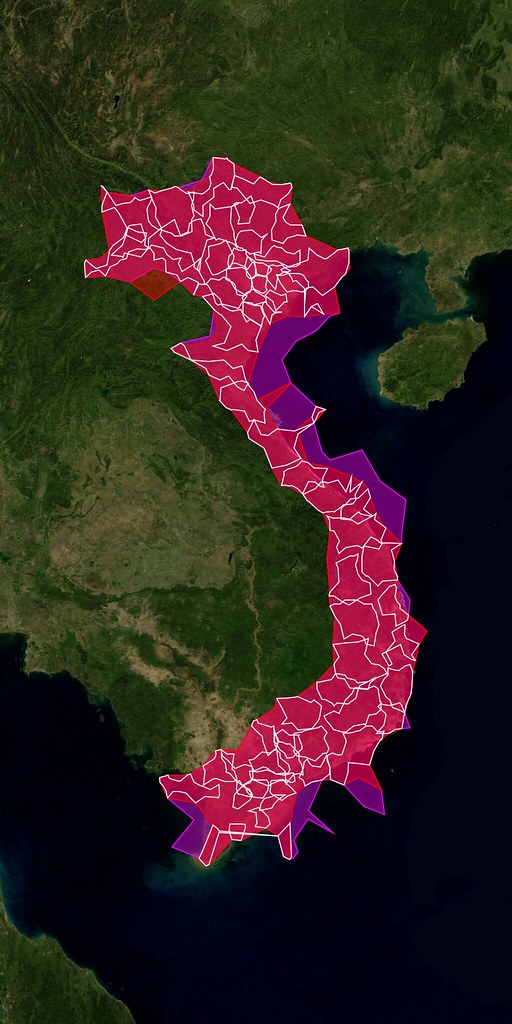
Aside from the quirkiness of the shapes themselves, it is worth remembering that some of them may just be wrong. We work pretty hard to prevent Undue Wronginess ™ from occurring but we’ve seen it happen in the past and so it would be, well, wrong not to acknowledge the possibility. On the other hand we don’t think we would have gotten this far if it wasn’t mostly right but if you see something that looks weird, please let us know
The dataset is available for download, today, from:
http://www.flickr.com/services/shapefiles/1.0/
The other exciting piece of news is that the Yahoo! GeoPlanet team has also released a public dataset of all their WOE IDs that include parent IDs, adjacent IDs and aliases (that’s just more fancy-talk for “different names for the same place”) under the Creative Commons Attribution License.
Which is pretty awesome, really.

They’ve also released the GeoPlanet Placemaker API. You feed it a big old chunk of free-form text and then “the service identifies places mentioned in text, disambiguates those places, and returns unique identifiers (WOEIDs) for each, as well as information about how many times the place was found in the text, and where in the text it was found.”
Again, Moar Awesome.
And a bit dorky. It’s true. The data, all by itself, won’t tell a story. It needs people and history to make that possible but as you poke around all this stuff don’t forget the value of having a big giant, and now open, database of unique identifiers and what is possible when you use them as a bridge between other things. Without WOE IDs we wouldn’t have been able to generate the shapefiles or do the Places project or provide a way to search for photos by place, rather than location.
Enjoy!
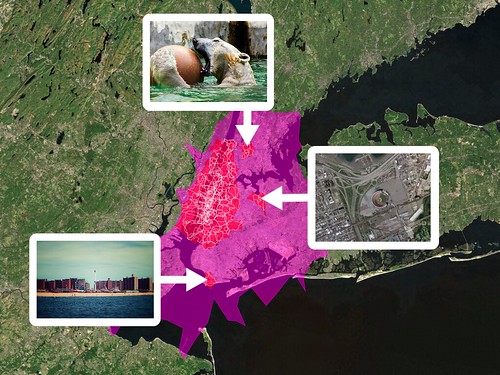
Oh, and those “unidentified” outliers, in New York City, that I mentioned in the last post about the donut hole shapefiles: The Bronx Zoo, Coney Island and Shea Stadium. Of course!