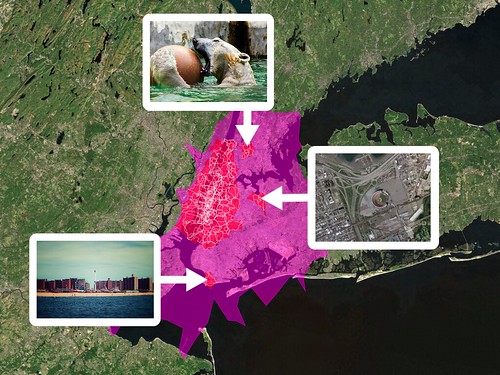
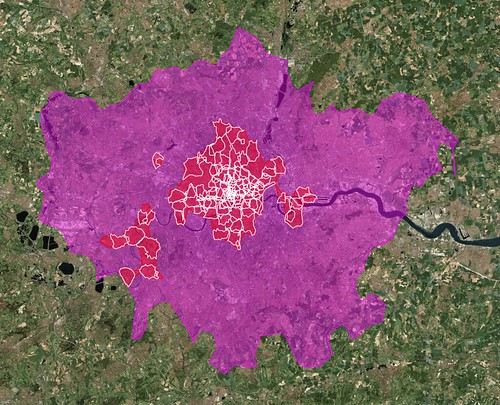
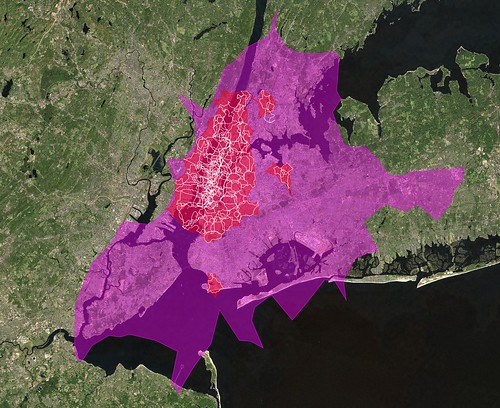
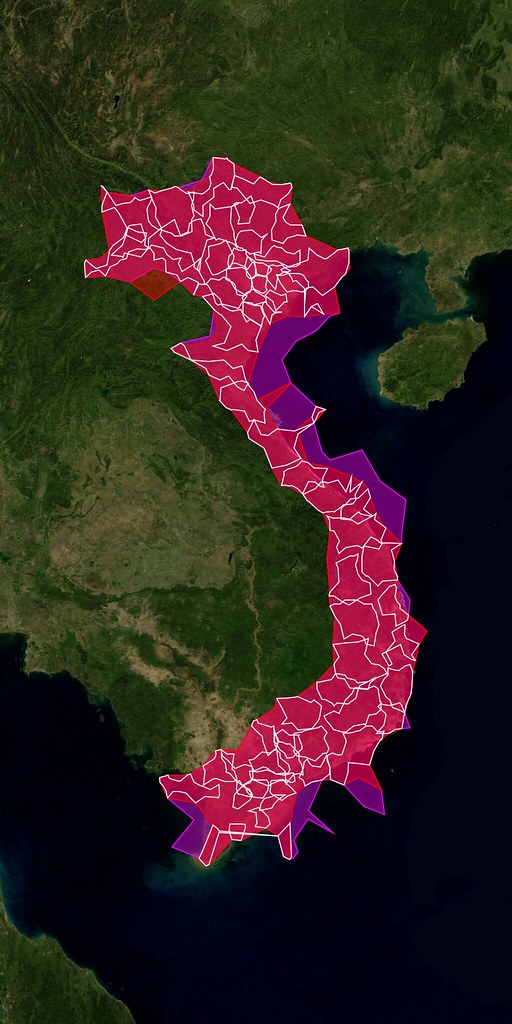
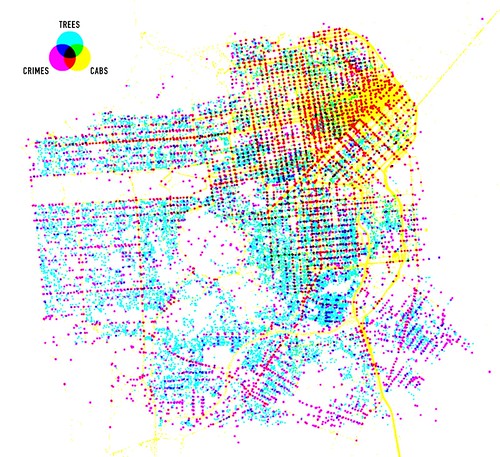
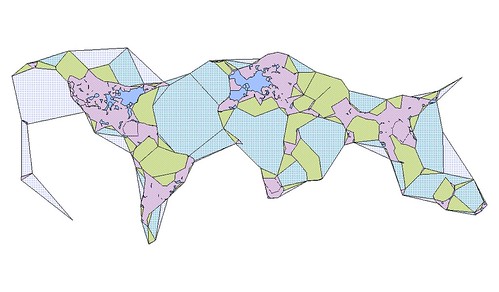
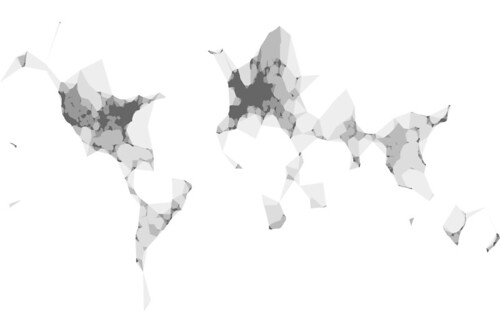
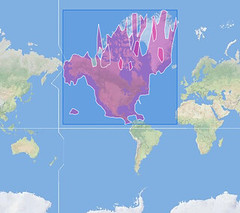
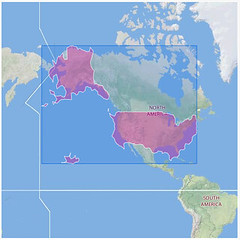
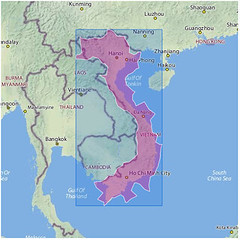
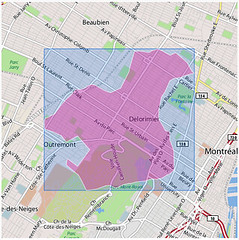
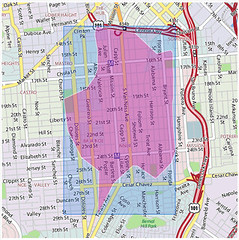
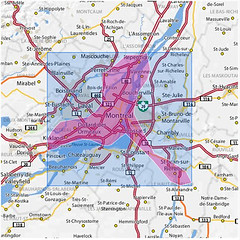
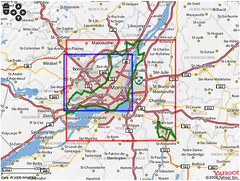
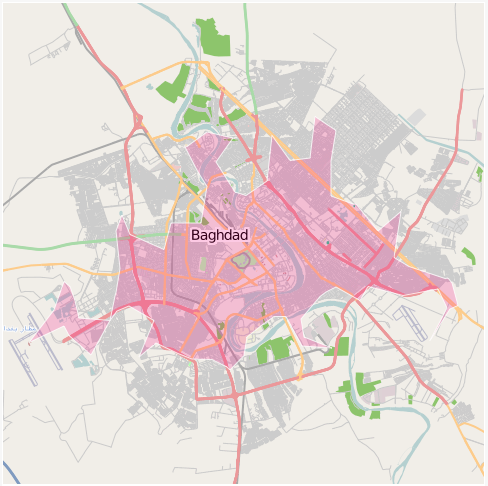
An embarrassingly long time ago we released the first public version of the Flickr Shapefiles. What does this have to do with Captain America and a cat? Nothing, really.
Anyway, we haven’t completely forgotten about shapefiles and have finally gotten around to generating a new batch (read about Alpha Shapes to find out how it’s done). When Aaron did the first run we had somewhere around ninety million (90M) geotagged photos. Today we have over one hundred and ninety million (190M) and that number is growing rapidly. Of course lots of those will fall within the boundaries of the existing shapes and won’t give us any new information, but some of them will improve the boundaries of old shapes, and others will help create new shapes where there weren’t any before. Version 1 of the dataset had shapes for around one hundred and eighty thousand (180K) WOE IDs, and now we have shapes for roughly two hundred and seventy thousand (270K) WOE IDs. Woo.
The dataset is available for download today, available for use under the Creative Commons Zero Waiver:
http://www.flickr.com/services/shapefiles/2.0/
Little Johnny JSON

Originally we provided the full dataset in our own home-grown XML format because, well, it seemed like a good idea. For version two we’re releasing the shapes in GeoJSON format. We think this is a Good Thing because unlike our old XML format, at least one other person in the world already knows how to read and write GeoJSON. For example, Our friends over at Stamen Design and SimpleGeo have created a ridiculously easy-to-use JavaScript library called Polymaps which of course reads GeoJSON out of the box. With a few lines of JavaScript you can render the Flickr shapefiles and start using them without all that pesky XML parsing stuff:
Or if GeoJSON doesn’t suit you you can use a free tool like ogr2ogr to convert it to something that does.
Layers

(photo by doug88888)
The GeoJSON format allows grouping of features (and their related geometries) into FeatureCollection objects. A FeatureCollection seems to be roughly equivalent to a layer in a typical GIS, or a placetype in WhereOnEarth-speak. To make the dataset a little easier to manage we decided to break the shapes up into FeatureCollections based on placetype; one each for continents, countries, regions (states), counties, localities (cities), and neighbourhoods. Each of these is its own GeoJSON file in the dataset.
Here’s an example of what one of our GeoJSON objects looks like:
{
"type": "FeatureCollection",
"name": "Flickr Shapes Public Dataset 2.0 - Regions",
"features": [
{
"type": "Feature",
"id": 2344541,
"properties": {
"woe_id": 2344541,
"place_id": "Cxf0SmObApi9R9T8",
"place_type": "region",
"place_type_id": 8,
"label": "Barbuda, AG, Antigua and Barbuda",
},
"geometry":
{
"type": "MultiPolygon",
"created": 1292444482,
"alpha": 0.03,
"points": 118,
"edges": 17,
"is_donuthole": 0,
"link": {
"href": "http://farm6.static.flickr.com/5209/shapefiles/2344541_20101215_724c4cae47.tar.gz",
},
"bbox": [-62.314453125,17.086019515991,-61.690979003906,17.93692779541],
"coordinates": [
[
[[-61.739044,17.587740], [-61.735268,17.546171], [-61.690979,17.426649], [-61.765137,17.413546]
... etc
A file is a single FeatureCollection object which holds an array of Features, which each hold a Geometry which is a MultiPolygon, which holds an array of Polygons which in turn each consist of an array of LinearRings. Got it?
You’ve Been Superseded
We’ve also included a separate file/layer called flickr_shapes_superseded.geojson. This is a FeatureCollection that consists of all the WOE IDs that have been “superseded”. Occasionally (too often?) a WOE ID needs to be retired and replaced with a new one. We keep up to date with these and are always reverse-geocoding against the latest WOE IDs. However, there are plenty of old photos (and Flickr shapes) that have been assigned to one of these old IDs, and we have shapes for them (currently a little more than nine thousand). A simple solution might be to just re-assign these photos to the new WOE IDs (when a WOE ID is retired its replacement is specified), or even just re-run the reverse-geocoding process. This may not be what the owner of the photo wants; it might come out with a different result than they had at first (which they may have been perfectly happy with), if the size and location of the WOE rectangle changed (which it probably did). So it’s a problem without a clear solution. And since we have data for these old WOE IDs we’ve included their associated shapes in the dataset. In most cases there will be shapes corresponding to the new WOE IDs that will over time become more and more accurate as more photos get uploaded and end up being assigned to the new WOE IDs. But you can have the old ones too.
WTF
Sometimes, Clustr just gets it wrong. As mentioned in previous posts many of the Flickr shapes are just plain weird. It may be due to a lack of data (i.e. source photos), a weakness of the algorithm, an inappropriate choice of the alpha parameter or (shame!) a plain old bug. One of the things that surprised us was that Clustr was not supposed to output inner rings, or polygons with holes. It turns out that it does. In the GeoJSON output this can cause some weirdness (depending on what you use to render the shapes) since the GeoJSON is formatted with the assumption that each ring is a distinct polygon, instead of possibly one part of a single polygon with holes in it. This and other weirdness are known issues and something we shall strive to fix in the future, however we felt it best to release the existing dataset now rather than spend forever trying to get it perfect, and end up not releasing anything at all.
You may also notice that unlike version 1 of the dataset, there is only a single shape per WOE ID. All of the previous versions of the shapes are still available via the Flickr API, but in the interests of keeping the file size down we’ve limited this download to just the latest versions of each shape.
And as always, there’s lots more to do.