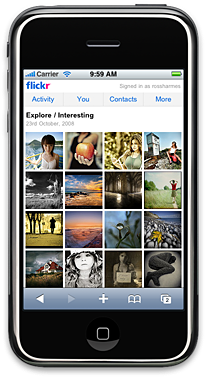
A few weeks ago we released a version of the Flickr site tailored specifically for the iPhone. Developing this site was very different from any other project I’ve worked on; there seems to be a new set of frontend rules for developing high-end mobile sites. A lot of the current best practices get thrown out the window in the quest for minimum page weight and fastest load times over slow cellular connections.
Here are a few of the lessons we learned (sometimes painfully) while developing this site.
1. Don’t Use a JavaScript Library or CSS Framework
This was one of the hardest things for me to come to terms with. I’m a huge fan of libraries, especially YUI, mostly because they allow me to spend my time creating new stuff instead of working around crazy browser quirks. But these libraries walk a fine line; by definition, they must work across a wide array of browsers and offer enough features to make them worth using. This means they potentially contain a lot of code that you don’t care about and won’t use. This code is dead weight to your site.
With such a high percentage of normal web users on broadband connections, we’ve gotten cavalier about what we can include in our pages. 250 KB of JavaScript or more isn’t uncommon for a large site these days. But for sites that are meant to be viewed over slow cellular connections like EDGE, 250 KB is an impossible amount of data. The only way to get the size of your JavaScript down is to selectively pull code out of libraries, and include only what you use. This means you can rip out code meant only for browsers that you won’t support (modular libraries like the new YUI 3.0 allow you to only include the code you use, preventing this problem somewhat).
The same goes for CSS. Frameworks make development faster and your final product more robust, but they, like the JavaScript libraries, include code for situations you won’t have to deal with. Every line in your CSS must be custom; each property must be scrutinized to ensure it’s needed.
2. Load Page Fragments Instead of Full Pages
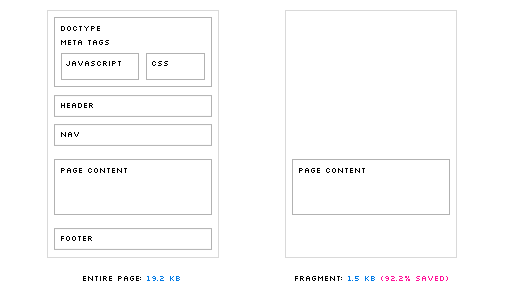
When navigating through a site, most of what changes from page to page is the actual content; the JavaScript, CSS, header and footer stay mostly the same. We can use this to our advantage by only loading the part of each page that changes. We did this by hijacking all links of the page: when a link is clicked, we intercept the event, fetch the page fragment using Ajax, and insert the HTML into a new div. This has several benefits:
- Since you control the entire life cycle of the page fetch, you can display loading indicators or a wireframe version of the page while new pages load
- All pages that have been fetched will exist within the DOM; clicking the back button (or clicking on a link for a page that has already been fetched) results in an instantaneous page load
- The page fragments are extremely small; ours are about 800 bytes (gzipped) on average
Using this system complicates your code a bit. You need JavaScript to handle the hijacking, the page fragment insertion, and the address bar hash changes (which allow the back and forward buttons to work normally). You also need your backend to recognize requests made with Ajax, and to only send the page content instead of the full HTML document. And lastly, if you want normal URLs to work, and each of your pages to be bookmarkable, you will need even more JavaScript.
Despite these downsides, the benefits can’t be ignored. The extra JavaScript code is a one-time cost, but the extra page content that we would have downloaded is saved for every page load. We found it was worth the complication and additional JS in order to dramatically reduce the time it took to load each page.
3. Don’t Build for Just One Device
It’s really tempting to build the site for just the iPhone: you can use modern CSS (including things like CSS3 selectors and transformations), you don’t have to hack around annoying browser quirks, and testing is extremely easy. But any single device, even one as ubiquitous as the iPhone, has a limited share of the mobile market, especially internationally. Rarely can you justify the cost of creating a one-off site for a very small number of your users.
Luckily the current generation of high-end mobile browsers is excellent in terms of support for modern features. Many phones use a WebKit derivative, including the iPhone, and Symbian and Android phones. Other phones either come with or can use Opera Mobile or the new mobile version of Firefox (called Fennec). For the most part, very few changes are needed in order to support these browsers.
Most of the differences lie in layout. It’s important to structure your pages around a grid that can expand as a percentage of the page width. This allows your layouts to work on many different screen sizes and orientations. The iPhone, for example, allows both landscape and portrait viewing styles, which have vastly different layout requirements. By using percentages, you can have the content fill the screen regardless of orientation. Another option is to detect viewport width and height, and use JavaScript to dynamically adjust classes based on those measurements (but we found this was overkill; CSS can handle most situations on its own).
4. Optimize Everything
The browsers on mobile devices operate under much stricter constraints than their desktop cousins. Slower CPUs, smaller amounts of memory, and smaller hard drives mean that less data can be cached. On the iPhone, for instance, only files smaller than 25 KB are cached. This puts very specific limits of the size of your files. For a large site like Flickr, 25 KB worth of JavaScript and CSS barely scratches the surface. To put our files under the limit, we ran everything through the YUI Compressor using the most aggressive settings. We ran all images through compression tools as well (we like pngout and Smushit), reducing each image file by an average of 40%. We also made heavy use of sprites, where possible.
In the end, we were able to go from 90+ second load times over EDGE to less than 7 for an empty cache experience. Using page fragments, we are able to load and display new pages in under a second (though the images in those pages take longer to load). These are not trivial gains, and make the difference between a good mobile experience and a one that is so awful the user gives up halfway through the page load.
5. Tell the User What is Happening
Once we hijacked all clicks actions in order to load page fragments, it wasn’t always clear to the user if anything was happening when they clicked on a link. This is especially true on touch devices, where it is difficult to know if the device even detected your action. To combat this problem, we added loading indicators to every link. These tell the user that something is happening, and reassures them that their action was detected. It also makes the pages seem to load much faster, since something is happening right away; if the indicators weren’t there, it would seem like nothing was happening for a few seconds, and then the page would load suddenly. In our testing, these indicators were the difference between a UI that seems snappy and responsive, and one that seemed slow and inconsistent.
One Easy Option
The iUI framework implements a lot of these practices for you, and might be a good place to start in developing any mobile site (though keep in mind it was developed specifically for the iPhone). We found it especially useful in the early stages of development, though eventually we pulled it out and wrote custom code to run the site.