We at Flickr are not ones to back down from a challenge. Especially when that challenge comes in webcomic form. And especially when that webcomic is xkcd. So, when we saw this xkcd comic we thought, “we’ve got to do that”:
In fact, we already had the technology in place to do these things. Like the woman in the comic says, determining whether a photo with GPS info embedded into it was taken in a national park is pretty straightforward. And, the Flickr Vision team has been working for the last year or so to be able to recognize more than 1000 things in images using deep convolutional neural nets. Incidentally, one of the things we’re pretty good at recognizing is birds!
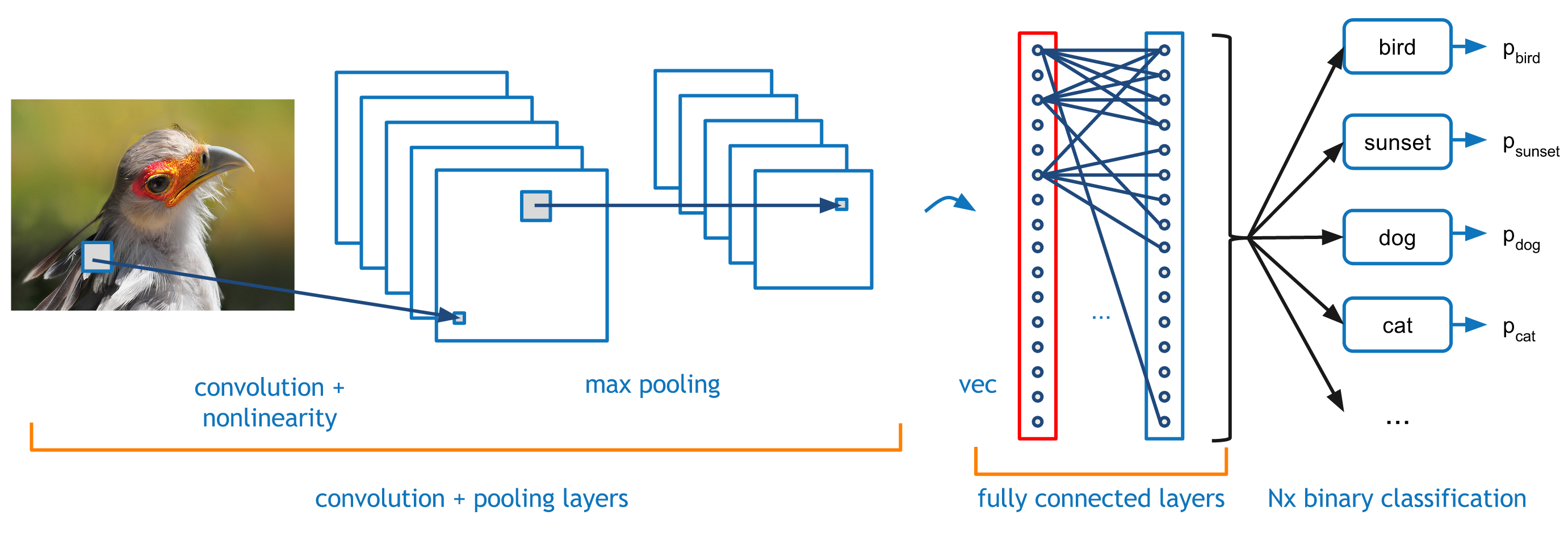
The thing we’re really excited to show off with PARK or BIRD is our image recognition technology. To recognize 1000+ things, we employ a deep convolutional neural network similar to the one depicted below.
This model transforms an input image into a representation in which different objects and scenes are easily distinguishable by a simple binary classification algorithm, like an SVM. It does this by passing the image through a series of layers, where each layer computes a function of the output of the layer below it.
Each successive one of these layers, after training on millions of images, has learned to recognize higher- and higher-level features of images and the ways these features go together to form different objects and scenes. For example, the first layer might recognize the most basic image features, such as short straight lines, corners, and small circular arcs. The next layer might recognize higher level combinations of those features, such as circles or other basic shapes. Further layers might recognize higher-level concepts, like eyes and beaks, and even further ones might recognize heads and wings. For an example of what this looks like, check out Figure 2 in this paper by Matt Zeiler and Rob Fergus.
As the image passes through these layers, they are “activated” in different ways depending on the features they’ve seen in the input image, and at the top of this network—after the image is transformed by the bottom layer, and that transformation of the image is transformed by the next layer, and that transformation of the transformation of the image is transformed by the next layer, and so on— a short floating-point vector summarizing all of the various activations at each layer is output. We pass this floating-point vector into more than 1000 binary classifiers, each of which is trained to give us a yes/no answer to identify a specific object/scene class. And, of course, one of those classes is birds!
The Flickr Vision team is already applying this deep network to Flickr photos to help people more more easily find what they’re looking for via Flickr search, and we plan to integrate it into Flickr in other cool ways in the future. We’re also working on other innovative computer vision and image recognition technologies that will make it easier for Flickr members to find and organize their photos.
Acknowledgements
The Flickr Vision and Search team is awesome and PARK or BIRD is built upon technologies that we all pitched in on. Here we all are (at least most of us), in all our beautiful glory. Thanks Vision/Search! Thanks also to Stephen Woods, Bart Thomee, John Ko, Mike Shema, and Sean Perkins, all of whom provided a lot of help getting PARK or BIRD off the ground.
If this all sounds like a challenge you’re interested in helping out with, you should join us! Flickr is hiring engineers, designers and product managers in our San Francisco office. Find out more at flickr.com/jobs.
This past summer we (Yahoo Labs and Flickr) released the YFCC100M dataset that is the largest and most ambitious collection of Flickr photos and videos ever, containing 99,206,564 photos and 793,436 videos from 581,099 different photographers. We’re super excited about the dataset, because it is a reflection of how Flickr and photography have evolved over the past 10 years. And it contains photos and videos of almost everything under the sun (and yes, loads of cats).
We’ve received a lot of emails and tweets asking for more details about the dataset, so in this blog post, we’ll gladly tell you. Each of the 100 million photos and videos is associated with a Creative Commons license that indicates how it may be used by others. The table below shows the complete breakdown of licenses in our dataset. Approximately 31.8% is marked for commercial use, while 17.3% has the most liberal license, which only requires attribution to the photographer.
License
Photos
Videos
17,210,144
137,503
9,408,154
72,116
4,910,766
37,542
12,674,885
102,288
28,776,835
235,319
26,225,780
208,668
The photos and videos themselves are very diverse. We’ve found photos showing street scenes captured as part of photographer Andy Nystrom‘s life-logging activities, photos of real-world events like protests and rallies, as well as photos of natural phenomena.
Steve Rhodes
Andy Nystrom
BJ Graf
To understand more about the visual content of the photos in the dataset, the Flickr Vision team used a deep-learning approach to find the presence of visual concepts, such as people, animals, objects, events, architecture, and scenery across a large sample of the corpus. There’s a diverse collection of visual concepts present in the photos and videos, ranging from indoor to outdoor images, faces to food, nature to automobiles.
Concept
Count
outdoor
32,968,167
indoor
12,522,140
face
8,462,783
people
8,462,783
building
4,714,916
animal
3,515,971
nature
3,281,513
landscape
3,080,696
tree
2,885,045
sports
2,817,425
architecture
2,539,511
plant
2,533,575
house
2,258,396
groupshot
2,249,707
vehicle
2,064,329
water
2,040,048
mountain
2,017,749
automobile
1,351,444
car
1,340,751
food
1,218,207
concert
1,174,346
flower
1,164,607
game
1,110,219
text
1,105,763
night
1,105,296
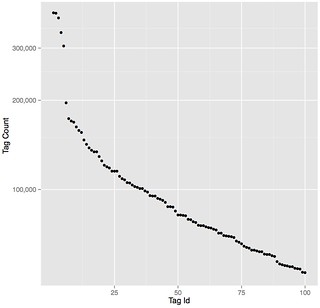
There are 68,971,123 photos and videos in the set that have user-annotated tags. If we look at specific tags used, we see it is very common for people to use the year of capture, the camera brand, place names, scenery, and activities as tags. The top 25 tags (excluding the years of capture) and how often they were used are listed below, as well as the tag frequency distribution for the 100 most-frequently used tags.
User Tag
Count
nikon
1,195,576
travel
1,195,467
usa
1,188,344
canon
1,101,769
london
996,166
japan
932,294
france
917,578
nature
872,029
art
854,669
music
826,692
europe
782,932
beach
758,799
united states
743,470
england
739,346
wedding
728,240
city
689,518
italy
688,743
canada
686,254
new york
685,311
vacation
680,142
germany
672,819
party
663,968
park
651,717
people
641,285
water
640,234
Some photos and videos (3,350,768 to be exact) carry machine tags. Noteworthy machine tags are those having the “siwild” namespace, referring to photos uploaded by scientists of the Smithsonian, and the “taxonomy” namespace, which refers to photos in which flora and fauna have been carefully classified. The most frequently occurring namespace, “uploaded,” refers to the applications used to share the photos on Flickr, which are principally the Flickr and Instagram iOS apps. Other interesting machine tags are those referring to the different filters that can be applied to a photo, or roughly 750,000 photos. Overall, most machine tags are related to food and drink, events, camera and application metadata, as well as locations.
Machine Tag
Count
uploaded
1,917,650
siwild
1,169,957
taxonomy
1,067,857
foursquare
894,265
exif
617,287
flickriosapp
538,829
geo
443,762
sequence
429,948
lastfm
313,379
flickrandroidapp
222,238
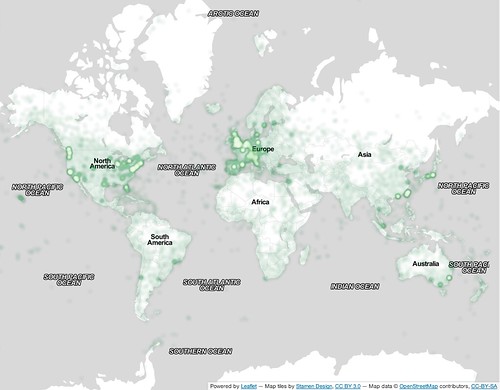
In terms of locations, the photos and videos in the dataset have been taken all over the world. In total, 48,366,323 photos and 103,506 videos were geotagged. The most popular cities where photos and videos were shot are concentrated in the United States, principally New York City, San Francisco, Los Angeles, Chicago, and Seattle; in Europe, they were principally London, Berlin, Barcelona, Rome and Amsterdam. There are also photos that have been taken in remote locations like Kiribati, icy places like Svalbard, and exotic places like Comoros. In fact, photos and videos from this dataset have been taken in 249 different territories (countries, islands, etc) around the world, and even in international waters or airspace.
Our dataset further reveals that there are many different cameras in use within the Flickr community. The Canon EOS 400D and 350D have a lead over the Nikon D90 (calm down…we’re not starting anything by saying that). Apple’s iPhones form the most popular type of cameraphone.
Make
Camera
Count
Canon
EOS 400D
2,539,571
Canon
EOS 350D
2,140,722
Nikon
D90
1,998,637
Canon
EOS 5D Mark II
1,896,219
Nikon
D80
1,719,045
Canon
EOS 7D
1,526,158
Canon
EOS 450D
1,509,334
Nikon
D40
1,358,791
Canon
EOS 40D
1,334,891
Canon
EOS 550D
1,175,229
Nikon
D7000
1,068,591
Nikon
D300
1,053,745
Nikon
D50
1,032,019
Canon
EOS 500D
1,031,044
Nikon
D700
942,806
Apple
iPhone 4
922,675
Nikon
D200
919,688
Canon
EOS 20D
843,133
Canon
EOS 50D
831,570
Canon
EOS 30D
820,838
Canon
EOS 60D
772,700
Apple
iPhone 4S
761,231
Apple
iPhone
743,735
Nikon
D70
742,591
Canon
EOS 5D
699,381
Our collection of 100 million photos and videos marks a new milestone in the history of datasets. The collection is one of the largest released for academic use, and it’s incredibly varied—not just in terms of the content shown in the photos and videos, but also the locations where they were taken, the photographers who took them, the tags that were applied, the cameras that were used, etc. The best thing about the dataset is that it is completely free to download by anyone, given that all photos and videos have a Creative Commons license. Whether you are a researcher, a developer, a hobbyist or just plain curious about online photography, the dataset is the best way to study and explore a wide sample of Flickr photos and videos. Happy researching and happy hacking!
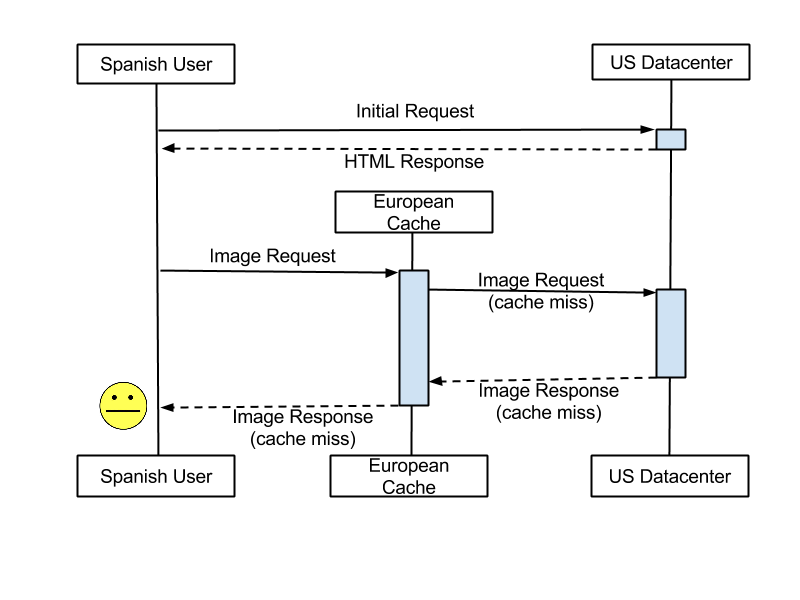
We’ve been working to make Flickr faster for our users around the world. Since the primary photo storage locations are in the US, and information on the internet travels at a finite speed, the farther away a Flickr user is located from the US, the slower Flickr’s response time will be. Recently, we looked at opportunities to improve this situation. One of the improvements involves keeping temporary copies of recently viewed photos in locations nearer to users. The other improvement aims to get a benefit from these caches even when a user views a photo that is not already in the cache.
Regional Photo Caches
For a few years, we’ve deployed regional photo caches located in Switzerland and Singapore. Here’s how this works. When one of our users in Vietnam requests a photo, we copy it temporarily to Singapore. When a second user requests the same photo, from, say, Kuala Lumpur, the photo is already present in Singapore. Flickr can respond much faster using this copy (only a few hundred kilometers away) instead of using the original file back in the US (over 8,000 km away).
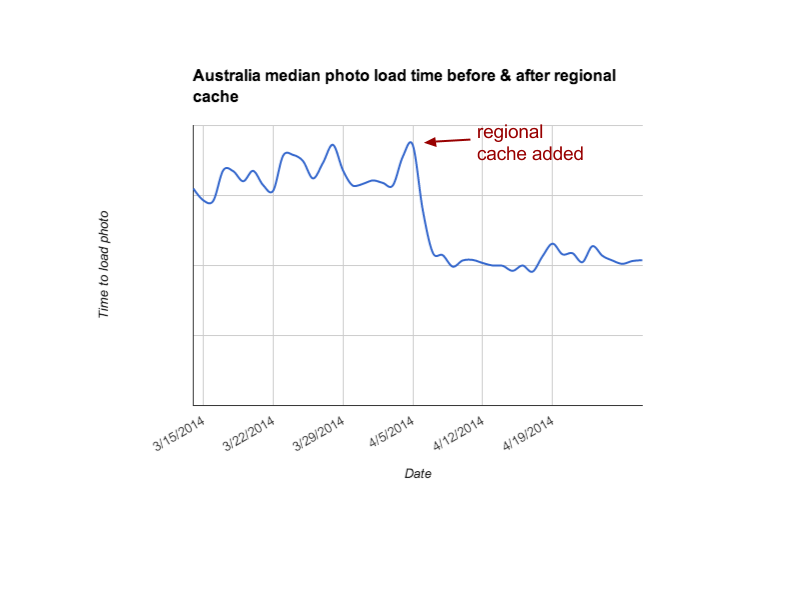
The first piece of our solution has been to create additional caches closer to our users. We expanded our regional cache footprint around two months ago. Our Australian users, among others, should now see dramatically faster load times. Australian users will now see the average image load about twice as fast as it did in March.
We’re happy with this improvement and we’re planning to add more regional caches over the next several months to help users in other regions.
Cache Prefetch
When users in locations far from the US view photos that are already in the cache, the speedup can be up to 10x, but only for the second and subsequent viewers. The first viewer still has to wait for the file to travel all the way from the US. This is important because there are so many photos on Flickr that are viewed infrequently. It’s likely that a given photo will not be present in the cache. One example is a user looking at their Auto Upload album. Auto uploaded photos are all private initially. Scrolling through this album, it’s likely that very few of the photos will be in their regional cache, since no other users would have been able to see them yet.
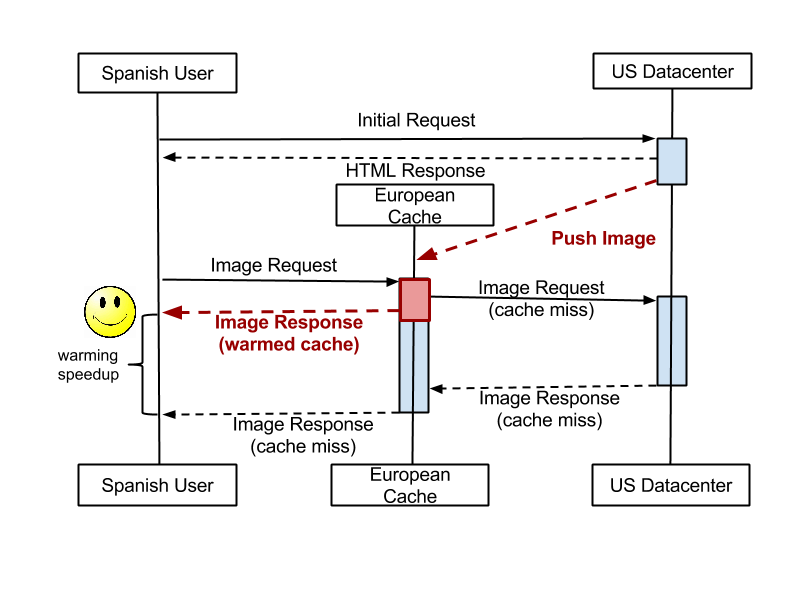
It turns out that we can even help the first viewer of a photo using a trick called cache warming.
To understand how caching warming works, you need to understand a bit about how we serve images. For example, say that I’m a user in Spain trying to access the photostream of a user, Martin Brock, in the US. When my request for Martin Brock’s Photostream at https://www.flickr.com/photos/martinbrock/ hits our backend servers, our code quickly determines the most recent photos Martin has uploaded that are visible to me, which sizes will fit best in my browser, and the URLs of those images. It then sends me the list of those URLs in an HTML response. The user’s web browser reads the HTML, finds the image URLs and starts loading them from the closest regional cache.
Standard image fetch
So you’re probably already guessing how to speed things up. The trick is to take advantage of the time in between when the server knows which images will be needed and the time when the browser starts loading them from the closest cache. This period of time can be in the range of hundreds of milliseconds. We saw an opportunity during this time to send the needed images over to the viewer’s regional cache in advance of their browser requesting the images. If we can “win the race” to do this, the viewer’s experience will be much faster, since images will load from the local cache instead of loading from the US.
To take advantage of this opportunity, we created a new “cache warming” process called The Warmer. Once we’ve determined which images will be requested (the first few photos in Martin’s photostream) we send a message from the API servers to The Warmer.
The Warmer listens for messages and, based on the user’s location, it determines from which of the Flickr regional caches the user will likely request the image. It then pushes the image out to this cache.
Optimized image fetch, with cache warming path indicated in red
Getting this to work well required a few optimizations.
Persistent connections
Yahoo encrypts all traffic between our data centers. This is great for security, but the time to set up a secure connection can be considerable. In our first iteration of The Warmer, this set up time was so long that we rarely got the photo to the cache in time to benefit a user. To eliminate this cost, we used an Nginx proxy which maintains persistent connections to our remote data centers. When we need to push an image out – a secure connection is already set up and waiting to be used.
Transport layer
The next optimization we made helped us reduce the cost of sending messages to The Warmer. Since the data we’re sending always fits in one datagram, and we also don’t care too much if a small percentage of these messages are never received, we don’t need any of the socket and connection features of TCP. So instead of using HTTP, we created a simple JSON format for sending messages using UDP datagrams. Another reason we chose to use UDP is that if The Warmer is not available or is reacting slowly, we don’t want that to cause slowdowns in the API.
Queue management
Naturally, some images are quite popular and it would waste resources to push them to the same cache repeatedly. So, the third optimization we applied was to maintain a list of recently pushed images in The Warmer. This simple “de-deduplication” cut the number of requests made by The Warmer by 60%. Similarly, The Warmer drops any incoming requests that are more than fifty milliseconds old. This “time-to-live” provides a safety valve in case The Warmer has fallen behind and can’t catch up.
Our initial implementation of the Warmer was in Python, using a ThreadPool. This allowed very rapid prototyping and worked great — up to a point. Profiling the Python code, we found a large portion of time spent in socket calls. Since there is so little code in The Warmer, we tried porting to Java. A nearly line-for-line translation resulted in a greater than 10x increase in capacity.
Results
When we began this process, we weren’t sure whether The Warmer would be able to populate caches before the user requests came in. We were pleasantly surprised when we first enabled it at scale. In the first region where we’ve deployed The Warmer (Western Europe), we observed a reduced median latency of more than 200 ms, 95% of photos requests sped up by at least 100 ms, and for a small percentage of photos we see over 400 ms reduction in latency. As we continue to deploy The Warmer in additional regions, we expect to see similar improvements.
Next Steps
In addition to deploying more regional photo caches and continuing to improve prefetching performance, we’re looking at a few more techniques to make photos load faster.
Compression
Overall Flickr uses a light touch on compression. This results in excellent image quality at the cost of relatively large file sizes. This translates directly into longer load times for users. With a growing number of our users connecting to Flickr with wireless devices, we want to make sure we can give users a good experience regardless of whether they have a high-speed LTE connection or two-bars of 3G in the countryside. An important goal will be to make these changes with little or no loss in image quality.
We are also testing alternative image encoding formats (like WebP). Under certain conditions WebP compression may offer better image quality at the same compression ratio than JPEG can achieve.
Geolocation and routing
It turns out it’s not straightforward to know which photo cache is going to give the best performance for a user. It depends on a lot of factors, many of which change over time — sometimes suddenly. We think the best way to do this is with a system that adapts dynamically to “Internet weather.”
Cache intelligence
Today, if a user needs to see a medium sized version of an image, and that version is not already present in the cache, the user will need to wait to retrieve the image from the US, even if a larger version of the image is already in the cache. In this case, there is an opportunity to create the smaller version at the cache layer and avoid the round-trip to the US.
Overall we’re happy with these improvements and we’re excited about the additional opportunities we have to continue to make the Flickr experience super fast for our users. Thanks for following along.
Like what you’ve read and want to make the jump with us? We’re hiring engineers, designers and product managers in our San Francisco office. Find out more at flickr.com/jobs.
Compass is a great thing. At Flickr, we’re actually quite smitten with it. But being conscious of your friends’ friends is important (you never know who they’ll invite to your barbecue), and we’re not so sure about this “Ruby” that Compass is always hanging out with. Then there’s Ruby’s friend Bundler who, every year at the Christmas Party, tells the same stupid story about the time the police confused him with a jewelry thief. Enough is enough! We’ve got history, Compass, but we just feel it might be time to try seeing other people.
Solving for Sprites
In order to find a suitable replacement (and for a bit of closure), we had to find out what kept us relying on Compass for so long. We knew the big one coming in to this great experiment: sprites. Flickr is a huge site with many different pages, all of which have their own image folders that need to be sprited together. There are a few different options for compiling sprites on your own, but we liked spritesmith for its multiple image rendering engines. This gives us some flexibility in dependencies.
A grunt task is available for spritesmith, but it assumes you are generating only one sprite. Our setup is a bit more complex and we’d like to keep our own sprite mixin intact so we don’t actually have to change a line of code. With spritesmith and our own runner to iterate over our sprite directories, we can easily create the sprites and output the dimensions and urls via a simple Handlebars template to a Sass file.
You could easily put all three of these rules in the same declaration, but we have some added flexibility in mind for our mixin.
It’s important to note that, because we’re using placeholders (the % syntax in Sass), nothing is actually written out unless we use it. This keeps our compiled CSS nice and clean (just like Compass)!
Here, our mixin uses the Sass file we generated to provide powerful and flexible sprites. Note: Although retina isn’t shown here, adding support is as simple as extending the Sass mixin with appropriate media queries. We wanted to keep the example simple for this post, but it gives you an idea of just how extensible this setup is!
Now that the big problem is solved, what about the rest of Compass’s functionality?
Completing the Package
How do we account for the remaining items in the Compass toolbox? First, it’s important to find out just how many mixins, functions, and variables are used. An easy way to find out is to compile with Sass and see how much it complains!
sass --update assets/sass:some-temp-dir
Depending on the complexity of your app, you may see quite a lot of these errors.
In total, we’re missing 16 mixins provided by Compass (and a host of variables). How do we replace all the great mixin functionality of Compass? With mixins of the same name, node-bourbon is a nice drop-in replacement.
What is the point of all this work again?
The Big Reveal
Now that we’re comfortably off Compass, how exactly are we going to compile our Sass? Well try not to blink, because this is the part that makes it all worthwhile.
Libsass is a blazing-fast C port of the Sass compiler that exposes bindings to modules like node-sass.
Just how fast? With Compass, our compile times were consistently around a minute and a half to two minutes. Taking care of spriting ourselves and using libsass for Sass compilation, we’re down to 5 seconds. When you deploy as often as we do at Flickr (in excess of 10 times a day), that adds up and turns into some huge savings!
What’s the Catch?
There isn’t one! Oh, okay. Maybe there are a few little ones. We’re pretty willing to swallow them though. Did you see that compile time?!
There are some differences, particularly with the @extend directive, between Ruby Sass and libsass. We’re anticipating that these small kinks will continue to be ironed out as the port matures. Additionally, custom functions aren’t supported yet, so some extensibility is lost in coming from Ruby (although node-sass does have support for the image-url built-in which is the only one we use, anyway).
With everything taken into account, we’re counting down the days until we make this dream a reality and turn it on for our production builds.
Like what you’ve read and want to make the jump with us? We’re hiring engineers, designers and product managers in our San Francisco office. Find out more at flickr.com/jobs.
We recently implemented Redis Sentinel at Flickr to provide automated Redis master failover for an important subsystem and we wanted to share our experience with it. Hopefully, we can provide insight into our experience adopting this relatively new technology and some of the nuances we encountered getting it up and running. Although we try to provide a basic explanation of what Sentinel is and how it works, anyone who is new to Redis or Sentinel should start with the excellent Redis and Sentinel documentation.
At Flickr we use an offline task processing system that allows us to execute heavyweight operations asynchronously from our API and web pages. This prevents these operations from making users wait needlessly for pages to render or API methods to return. Our task system handles millions of tasks per day which includes operations like photo uploads, user notifications and metadata edits. In this system, code can push a task onto one of several Redis-backed queues based on priority and operation, then forget about the task. Many of these operations are critical and we need to make sure we process at least 99.9999% of them (less than 1 in 1 million dropped). Additionally, we need to make sure this system is available to insert and process tasks at least 99.995% of the time – no more than about 2 minutes a month downtime.
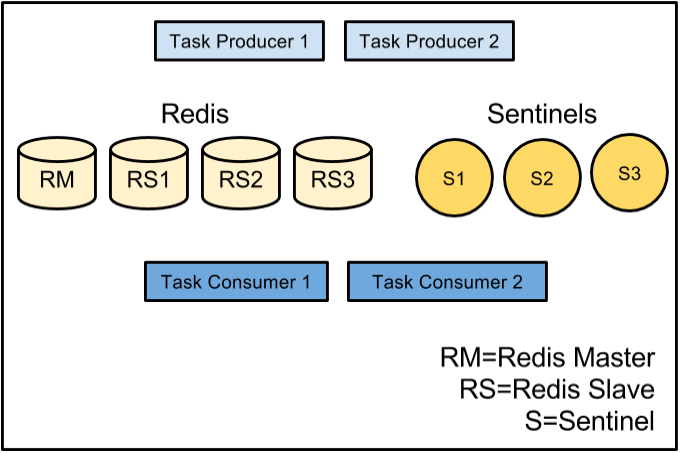
Until a few months ago our Redis BCP consisted of:
Upon master failure, the recovery plan included several manual steps: reconfiguring code to take the Redis master(s) offline and manually promoting a Redis slave (a mildly time consuming activity). Then we would rebuild and backfill unprocessed data from AOF files and error logs — a very time consuming activity. We knew if we lost a master we would have hours and hours of less-than-satisfying work to run the recovery plan, and there was potential for user impact and even a small amount of data loss. We had never experienced a Redis master failure, but we all know that such events are simply a matter of time. Overall, this fell far short of our durability and availability goals.
Configuring Sentinel
We started by installing and testing Sentinel in a development environment and the first thing we noticed was how simple Sentinel is to use and how similar the syntax is to Redis. We read Aphyr’s article and his back-and-forth blog duel with Salvatore and verified Aphyr’s warning about the “split brain” scenario. Eventually we decided the benefits outweighed the risks in our specific use case. During testing we learned about some Sentinel nuances and got a better feel for appropriate configuration values, many of which have little or no community guidance yet.
One such example was choosing a good value for the level-of-agreement setting, which is the number of Sentinels simultaneously reporting a host outage before automatic failover starts. If this value is too high then you’ll miss real failures and if it’s too low you are more susceptible to false alarms. (*thanks to Aleksey Asiutin(@aasiutin) for the edit!) In the end, we looked at the physical topology of our hosts over rack and switches and chose to run a relatively large number of Sentinel instances to ensure good coverage. Based on tuning in production we chose a value for level-of-agreement equal to about 80% of the Sentinel instances.
The down-after-milliseconds configuration setting is the time the Sentinels will wait with no response to their ping requests before declaring a host outage. Sentinels ping the hosts they monitor approximately every second, so by choosing a value of 3,100 we expect Sentinels to miss 3 pings before declaring host outage. Interestingly, because of Sentinel’s ping frequency we found that setting this value to less than 1,000 results in an endless stream of host outage notifications from the Sentinels, so don’t do that. We also added an extra 100 milliseconds (3,100ms rather than 3,000ms) to allow for some variation in Redis response time.
We chose a parallel-syncs value of 1. This item dictates the number of slaves that are reconfigured simultaneously after a failover event. If you serve queries from the read-only slaves you’ll want to keep this value low.
For an explanation of the other values we refer you to the self-documented default sentinel.conf file.
An interesting nuance of Sentinels is that they write state to their configuration file. This presented a challenge for us because it conflicted with our change management procedures. How do we maintain a dependably consistent startup configuration if the Sentinels are modifying the config files at runtime? Our solution was to create two Sentinel config files. One is strictly maintained in Git and not modified by Sentinel. This “permanent” config file is part of our deployment process and is installed whenever we update our Sentinel system configuration (i.e.: “rarely”). We then wrote a startup script that first duplicates the “permanent” config file to a writable “temporary” config file, then starts Sentinel and passes it the “temporary” file via command-line params. Sentinels are allowed to modify the “temporary” files as they please.
Interfacing with Sentinel
A common misconception about Sentinel is that it resides in-band between Redis and Redis clients. In fact, Sentinel is out-of-band and is only contacted by your services on startup. Sentinel then publishes notifications when it detects a Redis outage. Your services subscribe to Sentinel, receive the initial Redis host list, and then carry on normal communication directly with the Redis host.
The Sentinel command syntax is very similar to Redis command syntax. Since Flickr has been using Redis for a long time the adaptation of pre-existing code was pretty straightforward for us. Code modifications consisted of adding a few Java classes and modifying our configuration syntax. For Java-to-Redis interaction we use Jedis, and for PHP we use Predis and libredis.
Using Sentinel from Jedis is not documented as well as it could be. Here’s some code that we hope will save you some time:
// Verify that at least one Sentinel instance in the Set is available and responding.
// sentinelHostPorts: String format: [hostname]:[port]
private boolean jedisSentinelPoolAvailable(Set<String> sentinelHostPorts, String clusterName){
log.info("Trying to find master from available Sentinels...");
for ( String sentinelHostPort : sentinelHostPorts ) {
List<String> hostPort = Arrays.asList( sentinelHostPort.split(":") );
String hostname = hostPort.get(0);
int port = Integer.parseInt( hostPort.get(1) );
try {
Jedis jedis = new Jedis( hostname, port );
jedis.sentinelGetMasterAddrByName( clusterName );
jedis.disconnect();
log.info("Connected to Sentinel host:%s port:%d", hostname, port);
return true;
} catch (JedisConnectionException e) {
log.warn("Cannot connect to Sentinel host:%s port:%d”, hostname, port);
}
}
return false;
}
private Pool<Jedis> getDefaultJedisPool() {
// Create and return a default Jedis Pool object…
// ...
}
// ConfigurationMgr configMgr ⇐ your favorite way of managing system configuration (up to you)
public Pool<Jedis> getPool(ConfigurationMgr configMgr) {
String clusterName = configMgr.getRedisClusterName();
Set<String> sentinelHostPorts = configMgr.getSentinelHostPorts();
if(sentinels.size()>0) {
if(jedisSentinelPoolAvailable( sentinelHostPorts, clusterName )) {
return new JedisSentinelPool(clusterName, sentinelHostPorts);
} else {
log.warn(“All Sentinels unreachable. Using default Redis hosts.”);
return getDefaultJedisPool();
}
} else {
log.warn(“Sentinel config empty. Using default Redis hosts.”);
return getDefaultJedisPool();
}
}
Testing Sentinel at Flickr
Before deploying Sentinel to our production system we had several questions and concerns:
How will the system react to host outages?
How long does a failover event last?
How much of a threat is the split-brain scenario?
How much data loss can we expect from a failover?
We commandeered several development machines and installed a few Redis and Sentinel instances. Then we wrote some scripts that insert or remove data from Redis to simulate production usage.
We ran a series of tests on this setup, simulating a variety of Redis host failures with some combination of the commands: kill -9, the Sentinel failover command, and Linux iptables. This resulted in “breaking” the system in various ways.
Figure: Redis master failure
Figure: Network partition producing a ‘split-brain’ scenario
How will the system react to host outages?
For the most part we found Sentinel to behave exactly as expected and described in the Sentinel docs. The Sentinels detect host outages within the configured down-after-milliseconds duration, then send “subjective down” notifications, then send “objective down” notifications if the level-of-agreement threshold is reached. In this environment we were able to quickly and accurately test our response to failover events. We began with small test scripts, but eventually were able to run repeatable integration tests on our production software. Adding Redis to a Maven test phase for automated integration testing is a backlog item that we haven’t implemented yet.
How long does a failover event last?
The Sentinel test environment was configured with a down-after-milliseconds value of 3,100ms (just like production, see above). With this value Sentinels would produce a host outage notification after approximately 3 unsuccessful pings (one ping per second). In addition to the 3,100ms delay, we found there were 1-3 seconds in overhead for processing the failover event and electing a new Redis master, resulting in 4-6 seconds of total downtime. We are pretty confident we’ll see the same behavior in production (verified — see below).
How much of a threat is the “split-brain” scenario?
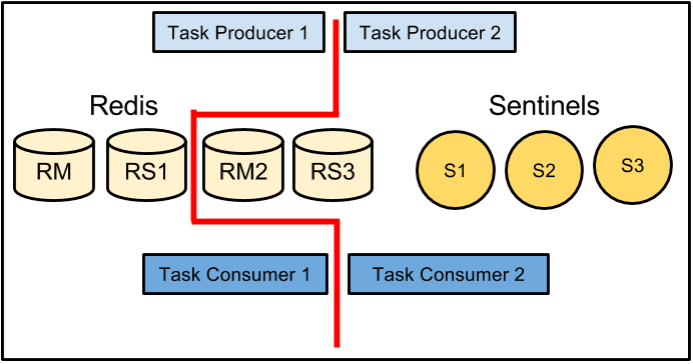
We carefully read Aphyr and Salvatore’s blog articles debating the threat of a “split brain scenario.” To summarize: this is a situation in which network connectivity is split, with some nodes still functioning on one side and other nodes continuing to function independently on the other side. The concern is the potential for the data set to diverge with different data being written to masters on both sides of the partition. This could easily create data that is either impossible or very difficult to reconcile.
We recreated this situation and verified that a network partition could create disjoint concurrent data sets. Removing the partition resulted in Sentinel arbitrarily (from our perspective) choosing a new master and losing all data written (post-partitioning) to the other master. So the question is: given our production architecture, what is the probability of this happening and is it acceptable given the significant benefit of automatic failover?
We looked at this scenario in detail considering all the potential failure modes in our deployment. Although we believe our production environment is not immune from split-brain, we are pretty sure that the benefits outweigh the risks.
How much data loss can we expect from a failover event?
After testing we were confident that Redis host outages could produce 4-6 seconds of downtime in this system. Rapid Sentinel automated failover events combined with reasonable backoff and retry techniques in the code logic were expected to further reduce data loss during a failover event. With Sentinel deployed and considering a long history of a highly stable Redis operation, we believed we could achieve 99.995% or more production availability – a few minutes of downtime per year.
Sentinel in Production
So how has Sentinel performed in production? Mostly it has been silent, which is a good thing. A month after finishing our deployment we had a hardware failure in a network switch that had some of our Redis masters behind it. Instead of having a potential scenario involving tens of minutes of user impact with human-in-the-loop actions to restore service, automatic failover allowed us to limit impact to just seconds with no human intervention. Due to the quick master failover and other reliability features in the code, only 270 tasks failed to insert due to the outage — all of which were captured by logging. Based on the volume of tasks in the system, this met our 99.9999% task durability goal. We did however decide to re-run a couple tasks manually and for certain critical and low-volume tasks we’re looking at providing even more reliability.
One more note from production experience. We occasionally see Sentinels reporting false “subjective down” events. Our Sentinel instances cohabitate host machines with other services. Occasionally these hosts get busy and we suspect these occasional load spikes affect the Sentinels’ ability to send and receive ping requests. But because our level-of-agreement is high, these false alarms do not trigger objective down events and are relatively harmless. If you’re deploying Sentinel on hosts that share other workloads, make sure that you consider potential impact of load patterns on those hosts and make sure you take some time to tune your level-of-agreement.
Conclusion
We have been very happy with Sentinel’s ease of use, relatively simple learning curve and brilliant production execution. So far the Redis/Sentinel combination is working great for us.
Like this post? Have a love of online photography? Want to work with us? Flickr is hiring engineers, designers and product managers in our San Francisco office. Find out more at flickr.com/jobs.
Recently, the team at Flickr has been working to improve photo search. Before our work began, Flickr only knew about photo metadata — information about the photo included in camera-generated EXIF data, plus any labels the photo owner added manually like tags, titles, and descriptions. Ironically, Flickr has never before been able to “see” what’s in the photograph itself.
Over time, many of us have started taking more photos, and it has become routine — especially with the launch last year of our free terabyte* — for users to have many un-curated photos with little or no metadata. This has made it difficult in some cases to find photos, either your own or from others.
So for the first time, Flickr has started looking at the photo itself**. Last week, the Flickr team presented this technology at the May meeting of the San Francisco Hadoop User’s Group at our new offices in San Francisco. The presentation focuses on how we scaled computer vision and deep learning algorithms to Flickr’s multi-billion image collection using technologies like Apache Hadoop and Storm. (In a future post here, we’ll describe the learning and vision systems themselves in more detail.)
Thanks very much to Amit Nithian and Krista Wiederhold (organizers of the SFHUG meetup) for giving us a chance to share our work.
If you’d like to work on interesting challenges like this at Flickr in San Francisco, we’d like to talk to you! Please look here for more information: http://www.flickr.com/jobs
If you read my recent post, you know that the Flickr API fully supports SSL. We’ve already updated our web and mobile apps to use HTTPS, and you no longer need to use “secure.flickr.com” to access the Flickr API via SSL. Simply update your code to call:
https://api.flickr.com/
We want communication with Flickr to be secure, all the time. So, we are tightening things up. Effective this week, all new API keys will work via HTTPS only. On June 27th, we will deprecate non-SSL access to the API. If you haven’t already made the change to HTTPS, now is the time!
Blackout Tests
In preparation for the June 27th cut-off date, we will run two “blackout” tests, each for 2 hours, so that you can ensure that API calls in your app no longer use HTTP. If you have changed your code to use HTTPS, your app should function normally during the blackout window. If you have not changed your code to use HTTPS, then during the 2-hr blackout window all API calls from your application will fail. The API will return a 403 status code for non-SSL requests.
Important Dates and Times
Change in new API keys: 6 May 2014 (If you request a new API key after 6 May, it will be issued for HTTPS only)
First blackout window: 3 June 2014, 10:00-12:00 Pacific Daylight Time (PDT) / 17:00-19:00 GMT
Second blackout window: 17 June 2014, 18:00-20:00 (PDT) / 18 June 2014, 01:00-03:00 GMT
In the API documentation, all of the endpoints have been updated to HTTPS. While OAuth adds security by removing the need to authenticate by username and password, sending all traffic over SSL further protects our users’ data while in transit.
For applications that use well-established HTTP client libraries, this switch should only require updating the protocol and (maybe) some updated configuration.
We realize that this change might be more difficult for some. We will follow the Developer Support Group closely, so please let us hear your questions. We will respond to them there, and will collect questions of general interest in the below FAQ.
FAQs About the Transition to SSL-Only for the Flickr API
Question: I only have a Flickr API key because I use an application or plugin that calls the Flickr API. Will that application or plugin continue to work after June 27th? Do I need to do something? Answer: An application or plugin that calls the Flickr API will stop working on June 27th if its owner does not make the changes we’ve described above. There are many, many providers of such services and plugins. We have notified them about this transition via email, blog post, developer lists, and on Twitter. As a user of such a service or plugin, you have no action to do for the transition unless the application or plugin owner asks you to upgrade to a new version. You also have the option to reach out to the application or plugin owner to assure yourself of their plans to handle this transition.
Question: Are all http://www.flickr.com urls going to be HTTPS from now on? Answer: Yes, all http://www.flickr.com urls returned by the API are now HTTPS, and all requests to HTTP in the browser are redirected to HTTPS.
Question: Should I switch my code to HTTPS right away or should I wait a bit? Answer: Switch now. The important thing is for your app to be changed to HTTPS before the first blackout on 3 June 2014. In fact, if your app is a mobile app, the earlier the better, so that your users will be more likely to upgrade before the first blackout.
Question: Do I need a new API key to replace my old one for this transition? Answer: No, you don’t need a new API key for this transition. You keep your existing key, and you change the code where you call the Flickr API, so that you call it with the HTTPS protocol, instead of HTTP. Change it to this:
https://api.flickr.com/
Question: What do I do with the new API key that is being issued by Flickr as of May 6? Answer: We are not automatically issuing a new key to you. What happened on 6 May was a change to how we handle new API keys. From now on, if you submit a request for a new key, that new key will only support calls to the Flickr API over HTTPS; it will not support calls to the API over HTTP. You do not need to request a new API key for this transition.
Question: I received your email about the API going SSL-only on June 27th. Do I need to do something? Answer: Maybe not. If you already call the API over HTTPS, then you’re good. No action needed. But if your code currently calls the API over HTTP, then, YES, you do need to do something. In your code you need to change the protocol to HTTPS. Like this:
https://api.flickr.com/
Question:If I use a protocol-less call to the API or match the protocol of the page that is making the call, do I need to change anything? Answer: Yes, you should change your calls to specifically use HTTPS. During the blackout period and starting on June 27th, protocol-less calls to the Flickr API from non-SSL pages will fail.
Question: Will the old https://secure.flickr.com endpoints continue to be supported in addition to the new https://api.flickr.com endpoints, or will only the latter be supported? Answer: Yes, https://secure.flickr.com endpoints will still be supported. If you use that today, your application will continue to work during the blackout windows and after 27 June.
tl;dr: Chrome’s DevTools: still awesome. Test carefully on small screens, mobile/tablets. Progressively enhance “extraneous”, but shiny, features where appropriate.
Building a fast, fun Slideshow / Web Page Hybrid
Every so often, dear reader, you may find yourself with a unique opportunity. Sometimes it’s a chance to take on some crazy ideas, break the rules and perhaps get away with some front-end skullduggery that wouldn’t be allowed, nor encouraged under normal circumstances. In this instance, Flickr’s newest Signed-Out Homepage turned out to be just that sort of thing.
The 2014 signed-out flickr.com experience (flickr.com/new/) is a hybrid, interactive blend of slideshow and web page combining scroll and scaling tricks, all the while highlighting the lovely new Flickr mobile apps for Android and iPhone with UI demos shown via inline HTML5 video and JS/CSS-based effects.
In 2013, we covered performance details of developing a vertical-scrolling page using some parallax effects, targeting and optimizing for a smooth experience. In 2014, we are using some of the same techniques, but have added some new twists and tricks. In addition, there is more consideration for some smaller screens this year, given the popularity of tablet and other portable devices.
Briefly:
Fluid slideshow-like UI, scale3d() and zoom-based scaling of content for larger screens
Timeline-based HTML transition effects, synced to HTML5 video
“Hijacking” of touch/mouse/keyboard scroll actions, where appropriate to experience
Background parallax, scale/zoom and blur effects (where supported)
Usability Considerations: Scrolling
In line with current trends, our designers intended to have a slideshow-like experience. The page was to be split into multiple “slides” of a larger presentation, with perhaps some additional navigation elements and cues to help the user move between slides.
Out in the wild, implementations of the slideshow-style web page widely in their flexibility. Controlling the presentation like this is challenging and dangerous from a technical perspective, as the first thing you are doing is trying to prevent the browser from doing what it does well (arbitrary bi-directional scrolling, in either staggered steps or smooth inertia-based increments depending on the method used) in favour of your own method which is more likely to have holes in its implementation.
If you’re going to hijack a basic interaction like scrolling, attention to detail is critical. Because you’ve built something non-standard, even in the best case the user may notice and think, “That’s not how it normally scrolls, but it responded and now I’m seeing the next page.” If you’re lucky, they could be using a touchpad to scroll and may barely notice the difference.
By carefully managing the display of content to fit the screen and accounting for common scroll actions, we are able to confidently override the browser’s default scroll behaviour in most cases to present a unique experience that’s a hybrid of web page and slideshow.
The implementation itself is fairly straightforward; you can listen to the mouse wheel event (triggered both by physical wheels and touchpads), determine which direction the user is moving in, debounce further wheel events and then run an animation to transition to the next slide. It’s imperfect and subject to double-scrolling, but most users will not “throw” the scroll so hard that it retains enough inertia and continues to fire after your animation ends.
Additionally, if the user is on an OS that shows a scrollbar (i.e., non-OS X or OS X with a mouse plugged in), they should be able to grab and drag the scrollbar and navigate through the page that way. Don’t even try messing with that stuff – your users will kill you with pitchforks, ensuring you will be sent to Web Developer Usability Anti-Pattern Hell. You will not pass Go, and will not collect $200.
Content Sizing
In order to get a slideshow-like experience, each “slide” had to be designed to fit within common viewport dimensions. We assumed roughly 1024×768, but ended up targeting a minimum viewport height of around 600px – roughly what you’d get on a typical 13″ MacBook laptop with a maximized window and a visible dock. In retrospect, that doesn’t feel like a whole lot of space; it’s important to consider if you’re also aiming to display your work on mobile screens, as well.
Once each slide fit within our target dimensions, the positioning of each slide’s content could be tightly controlled. Each is in a relatively-positioned container so they stack vertically as normal, and the height is at minimum, the height of the viewport or the natural offsetHeight dictated by the content itself. Reasonable defaults are first assigned by CSS, and future updates are done via JS at initial render and on window.resize().
With each slide being one viewport high, one might assume we could then let the user scroll freely through the content, perusing at will. We decided to go against this and control the scrolling for a few reasons.
Web browsers’ default “page down” (spacebar or page up/down keys, etc.) does not scroll through 100% of the viewport, as we would want in this case; there is always some overlap from the previous page. While this is completely logical considering the context of reading a document, etc., we want to scroll precisely to the beginning of the next frame. Thus, we use JS to animate and set scrollTop.
Content does not normally shift vertically when the user resizes their browser, but will now due to JS adjusting each slide’s height to fit the viewport as mentioned. Thus, we must also adjust scrollTop to re-align to the current slide, preventing the content from shifting as the user resizes the window. Sneaky.
We want to know when a user enters and leaves a slide, so we can play or reset HTML5 <video> elements and related animations as appropriate. By controlling scroll, we have discrete events for both.
Content Scaling
Given that we know the dimensions of our content and the dimensions of the browser viewport, we are able to “zoom” each slide’s absolutely-positioned content to fit nicely within the viewport of larger screens. This is a potential minefield-type feature, but can be applied selectively after careful testing. Just like min and max-width, you can implement your own form of min-scale and max-scale.
Scaling raster-based content, of course, is subject to degrading pretty quickly in terms of visual quality. To help combat pixelation, scaling is limited to a reasonable maximum – i.e., 150% – and where practical, retina/hi-DPI (@2x) assets are used for elements like icons, logos and so forth, regardless of screen type. This works rather well on standard LCDs. On the hi-DPI side, thankfully, huge retina screens are not common and there is less potential for scaling.
Depending on browser, content scaling can be done via scale3d()or the old DOM .style.zoom property (yes, it wasn’t just meant for triggering layout in old IE.) From my findings, Webkit appears to rasterize all content before scaling it. As a result, vector-based content like text is blurred in Webkit when using scale3d(). Thus, Wekbit gets the older .style.zoom approach. Firefox doesn’t support .style.zoom, but does render crisp text when using scale3d().
There are few tricks to getting scaling to work, short of updating it alongside initial render and window.resize() events. overflow: hidden may need to be applied to the frame container, in the scale3d() case.
JS Performance: window.onscroll() and window.onresize()
It’s no secret: scroll and resize are two popular JavaScript events that can cause a lot of layout thrashing. Some cost is incurred by the browser’s own layout, decoding of images, compositing and painting, but most notable thrashing is caused by developers attaching expensive UI refresh-related functions to these events. Parallax effects on scrolling is a popular example, but resize can trigger it as well.
In this case, synchronous code fires on resize so that the frames immediately resize themselves to fit the new window dimensions, and the window’s scrollTop property is adjusted to prevent any vertical shift of content. This is expensive, but is justified in keeping the view consistent with what the user would expect during resize.
Scroll events on this page are throttled (that is, there is not a 1:1 event-firing-to-code-running ratio) so that the parallax, zoom and blur effects on the page – which can be expensive when combined – are updated at a lower, yet still responsive interval, thus lowering the load on rendering during scroll.
Fun stuff: Background sizing, Parallax, Scale-based Motion, Blur Effects via Opacity, Video/HTML Timelines
The parallax thing has been done before, by Flickr and countless other web sites. This year, some twists on the style included a gradual blur effect introduced as the user scrolls down the page, and in some cases, a slight motion effect via scaling.
Backgrounds and Overlays
For this fluid layout, the design needed to be flexible enough that exact background positioning was not a requirement. We wanted to retain scale, and also cover the browser window. A fixed-position element is used in this case, width/height: 100%, background-size: cover and background-position: 50% 0px, which works nicely for the main background and additional image-based overlays that are sometimes shown.
The background tree scene becomes increasingly blurry as the user scrolls through the page. CSS-based filters and canvas were options, but it was simpler to apply these as background images with identical scaling and positioning, and overlay them on top of the existing tree image. As the user scrolls through the top half of the page, a “semi-blur” image is gradually made visible by adjusting opacity. For the latter half, the semi-blur is at 100% and a third “full-blur” image is faded in using the same opacity approach.
Where supported, the background also also scales up somewhat as the user scrolls through the page, giving the effect of forward motion toward the trees. It is subtle when masked by the foreground content, but still noticeable.
Here is an example with the content hidden, showing how the background moves during scroll.
In terms of parallax, a little extra image is needed for the background to be able to move. Thus, the element containing the background images is width: 100% and height: 110%. The background is scaled by the browser to fit the container as previously described, and the additional 10% height is off-screen “parallax buffering” content. This way, the motion is always relative in scale and consistent with the background.
HTML5 Video and “Timelines” in JS
One of the UI videos in this page shows live filters being applied – “Iced Tea”, “Throwback” and so on, and we wanted to have those filters showing outside the video area also if possible. Full-screen video was considered briefly, but wasn’t appropriate for this design. Thus, it was JS to the rescue. By listening to a video’s timeupdate event and watching the currentTime attribute, events could be queued in JS with an associated time, and subsequently fired roughly in sync with effects in the video.
In this case, the HTML-based effects were simple CSS opacity transitions triggered by changing className values on a parent element.
When a user leaves a slide, the video can be reset when the scroll animation completes, and any filter / transition-based effects can also be faded out. If the user returns to the slide, the video and effects seamlessly restart from their original position.
HTML5 Video Fallbacks
Some clients treat inline HTML5 video specially, or may lack support for the video formats you provide. Both MP4 (H.264) and WebM are used in this case, but there’s still no guarantee of support. Tablet and mobile devices are unlikely to allow auto-play of video, may show a play arrow-style overlay, or may only play video in full-screen mode. It’s good to keep these factors in mind when developing a multimedia-rich page; many users are on smaller screens – tablets, phones and the like – which need to be given consideration in terms of their features and support.
Some clients also support a poster attribute on the video element, which takes a URL to a static poster frame image. This can sometimes be a good fallback, where a device may have video support but fails to decode or play the provided video assets. Some browsers don’t support the poster attribute, so in those instances you may want to listen for error events thrown from the video element. If it looks like the video can’t be played, you can use this event as a signal to hide the video element with an image of the poster frame URL.
Considerations for Tablets and Smaller Screens
The tl;dr of this section: Start with a simple CSS-only layout, and (carefully) progressively enhance your effects via JS depending on the type of device.
Smaller devices don’t have the bandwidth, CPU or GPU of their laptop and desktop counterparts. Additionally, they typically do not fire resize and scroll events with the same rapid interval because they are optimized for touch and inertia-based scrolling. Therefore, it is best to avoid “scroll hijacking” entirely; instead, allow users to swipe or otherwise scroll through the page as they normally would.
Given the points about video support and auto-play not being allowed, the benefits offered by controlled scrolling are largely moot on smaller devices. Users who tap on videos will find that they do play where supported, in line with their experience on other web sites. The iPad with iOS 7 and some Samsung tablets, for example, are capable of playing inline video, but the iPhone will go to a full-screen view and then return to the web page when “done” is tapped.
Without controlled scrolling and regular scroll events being fired, the parallax, blur and zoom effects are also not appropriate to use on smaller screens. Even if scroll events were fired or a timer were used to force regular updates at a similar interval, the effects would be too heavy for most devices to draw at any reasonable frame rate. The images for these effects are also fairly large, contributing to page weight.
Rendering Performance
Much of what helped for this page was covered in the 2013 article, but is worth a re-tread.
Do as little DOM “I/O” as possible.
Cache DOM attributes that are expensive (cause layout) to read. Possible candidates include offsetWidth, offsetHeight, scrollTop, innerWidth, innerHeight etc.
Throttle your function calls, particularly layout-causing work, for listeners attached to window scroll and resize events as appropriate.
Use translate3d() for moving elements (i.e., fast parallax), and for promoting selected elements to layers for GPU-accelerated rendering.
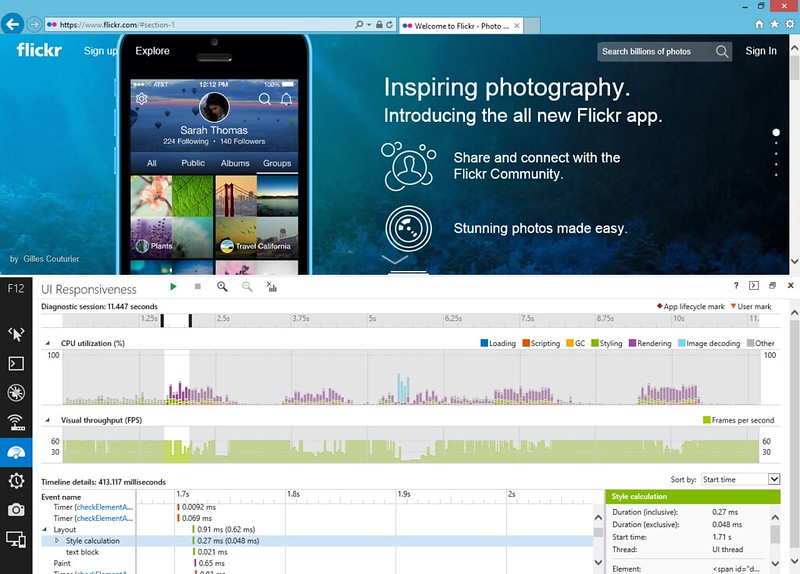
It’s helpful to look at measured performance in Chrome’s DevTools “Timeline” / frames view, and the performance pane of IE 11’s “F12 Developer Tools” during development to see if there are any hotspots in your CSS or JS in particular. It can also be helpful to have a quick way to disable JS, to see if there are any expensive bits present just when scrolling natively and without regular events firing. JS aside, browsers still have to do layout, decode, resize and compositing of images for display, for example.
Chrome DevTools: Initial page load, and scroll-through. There are a few expensive image decode and resize operations, but overall the performance is quite smooth.
IE 11 + Windows 8.1, F12 Developer Tools: “UI Responsiveness” panel. Again, largely smooth with a few expensive frames here and there. The teal-coloured frames toward the middle are related to image decoding.
For the record, I found that Safari 7.0.3 on OS X (10.9.2) renders this page incredibly smoothly when scrolling, as seen in the demo videos. I suspect some of the overhead may stem from JS animating scrollTop. If I were to do this again, I might look at using a transition and applying something sneaky like translate3d() to move the whole page, effectively bypassing scrolling entirely. However, that would require eliminating the scrollbar altogether for usability.
What’s Next?
While a good number of Flickr users are on desktop or laptop browsers, tablets and mobile devices are here to stay. With a growing number of users on various forms of portable web browsers, designers and developers will have to work closely together to build pages that are increasingly fluid, responsive and performant across a variety of screens, platforms and device capabilities.
Did I mention we’re hiring? We have openings in our San Francisco office. Find out more at flickr.com/jobs.
Sometime in the last few months, we went and updated our API SSL endpoints. Shame on us for not making a bigger deal about it!
In the past, to access the Flickr API via SSL you needed to use the “secure.flickr.com” subdomain… Not anymore!
Now calling the API via SSL is as easy as updating your code to call:
https://api.flickr.com/
In fact, it’s so easy that we want everyone to use it.
You’ll notice in the API documentation that all of the endpoints have been updated to https. While OAuth adds security by removing the need to authenticate by username and password, sending all traffic over SSL will further protect our users’ data while in transit.
Later this year we will be migrating the Flickr API to SSL access only. We’ll let you know the exact date in advance, and will run a blackout test before the big day. For applications that use well established HTTP client libraries, this should only require updating the protocol and (maybe) some updated configuration. We’ll also be working with API kit developers, so updating many apps will be a git pull away.
Of course we realize that this change might be more difficult for some. We’ll be following the Developer Support Group closely, so please let us hear your questions, comments, and concerns.
This is the first step of many improvements that we’ll be making to the API and our developer tools this year, and we’ll post additional details and timelines as we go. Want to help? We’re hiring!
This summer I had the unforgettable opportunity to work side-by-side with the some of the smartest, photography-loving software engineers I’ve ever met. Looking back on my first day at Flickr HQ – beginning with a harmonious welcome during Flickr Engineering’s weekly meeting – I can confidently say that over the past ten weeks I have become a much better software engineer.
One of my projects for the summer was to build a new and improved locking manager that controls the distribution of locks for offline tasks (or OLTs for short). Flickr uses OLTs all the time for data migration, uploading photos, updates to accounts, and more. An OLT needs to acquire a lock on a shared resource, such as a group or an account, to prevent other OLTs from accessing the same resource at the same time. The OLT will then release the lock when it’s done modifying the shared data. Myles wrote an excellent blog post on how Flickr uses offline tasks here.
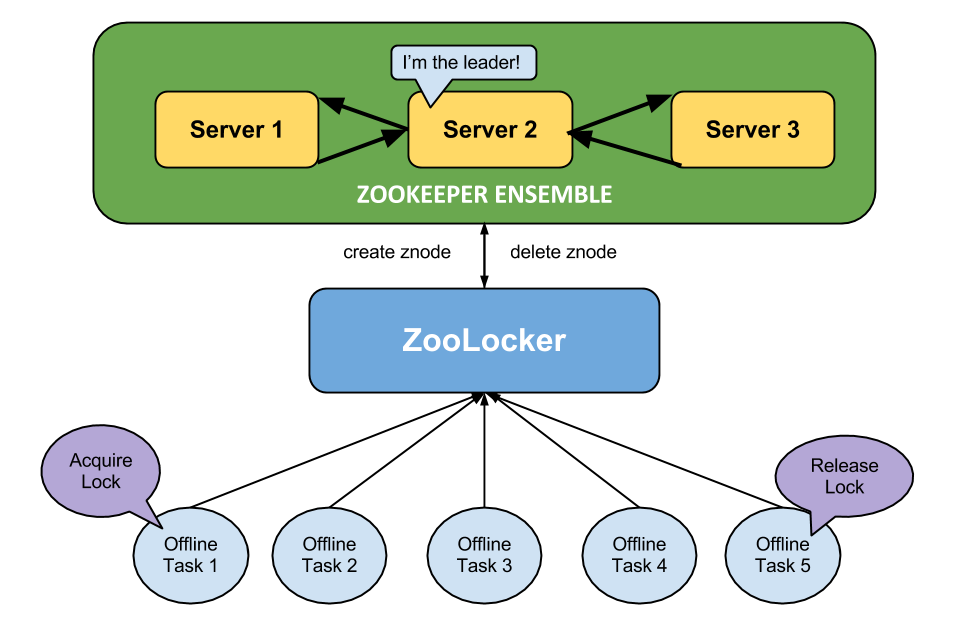
When building a distributed lock system, we need to take into account a couple of important details. First, we need to make sure that all the lock servers are consistent. One way to maintain consistency is to elect one server to act as a master and the remaining servers as slaves, where the master server is responsible for data replication among the slave servers. Second, we need to account for network and hardware failures – for instance, if the master server goes down for some reason, we need to quickly elect a new master server from one of the slave servers. The good news is, Apache ZooKeeper is an open-source implementation of master-slave data replication, automatic leader election, and atomic distributed data reads and writes.
Offline tasks send lock acquire and release requests through ZooLocker. ZooLocker in turn interfaces with the ZooKeeper cluster to create and delete znodes that correspond to the individual locks.
In the new locking system (dubbed “ZooLocker”), each lock is stored as a unique data node (or znode) on the ZooKeeper servers. When a client acquires a lock, ZooLocker creates a znode that corresponds to the lock. If the znode already exists, ZooLocker will tell the client that the lock is currently in use. When a client releases the lock, ZooLocker deletes the corresponding znode from memory. ZooLocker stores helpful debugging information, such as the owner of the lock, the host it was created on, and the maximum amount of time to hold on to the lock, in a JSON-serialized format in the znode. ZooLocker also periodically scans through each znode in the ZooKeeper ensemble to release locks that are past their expiration time.
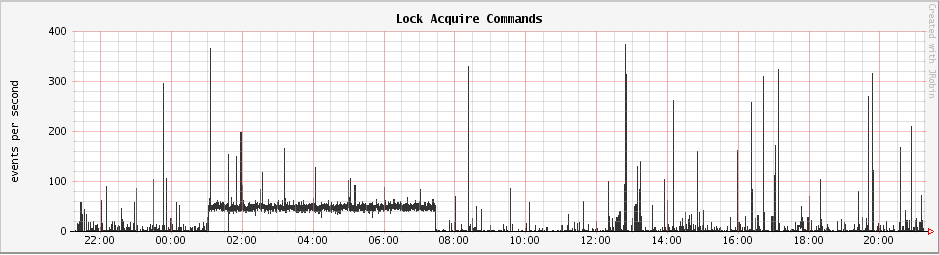
My locking manager is already serving locks in production. In spite of sudden spikes in lock acquire and release requests by clients, the system holds up pretty well.
A graph of the number of lock acquire requests in ZooLocker per second
My summer internship at Flickr has been an incredibly valuable experience for me. I have demystified the process of writing, testing, and integrating code into a running system that millions of people around the world use each and every day. I have also learned about the amazing work going on in the engineering team, the ups and downs the code deploy process, and how to dodge the incoming flying finger rockets that the Flickr team members fling at each other. My internship at Flickr is an experience I will never forget, and I am very grateful to the entire Flickr team for giving me the opportunity to work and learn from them this summer.