

Yes, I got a bit emotional at the third OpenStreetMap conference, held in the CCC, Amsterdam last weekend — mainly because this globe we are on is the only one we know — we really are mapping our universe, doing it our way. Creating the world we want to live in. I thought it worth while to say “Thanks” to some people. Being British, the feeling of being a bit foolish stopped me from being too effusive!
A couple weeks ago I had the pleasure of attending, and the privilege of speaking at, the State of the Map conference in Amsterdam. I told the story of how we came to use Open Street Maps (OSM), how it works on the backend and talked a little bit about what we’d like to do next: Moving beyond “bags of tiles”, a better way to keep up to date with changes to the OSM database and, for good measure, a little bit of tree-hugging at the end.
Most of all, though, I wanted to take the opportunity to thank the OSM community. To thank them for making Flickr, the thing that we care about and work on all day, better. To thank them for proving the nay-sayers wrong.
To say that OSM started with an audacious plan (to map the entire world by “hand” one neighbourhood and one person at a time) would be an understatement. You would have been forgiven, at the time, for laughing.
And yet, in a few short years they are well on their way having nurtured both a community of users and an infrastructure of tools that makes it hard to ever imagine a world without Open Street Maps. In the U.K. alone, as Muki Haklay demonstrated, they have produced a free and open dataset whose coverage and fidelity rivals those created by the Ordinance Survey with its government funding and 250-year head start.
That is really exciting both because of the opportunities that such a rich and comprehensive dataset provide but also because it proves what is possible. The Internets are still a pretty great place that way.

There were too many excellent talks to list them all, but here’s a short (ish) list that betrays some of my interests and biases:
-
Harry Wood’s talk on tagging in OSM. I actually missed this talk and after seeing the slides I am doubly disappointed. Open Street Map is not just the raw geographic data that people collect but also all the metadata that is used to describe it. OSM uses a simple tagging system for recording “map features” and Harry’s talk on managing the chaos, navigating the disputes and juggling the possibilities looked like it was really interesting.
(The title of this post is, in fact, a gentle poke at the black sheep of the OSM tagging world. There really are map features tagged “horse=yes” which is mostly hilarious until you remember how much has been accomplished with a framework that allows for tags like that.)
-
The Sunday afternoon maps-and-history love-fest that included Frankie Roberto’s “Mapping History on Open Street Map“, Tim Water’s “Open Historical Maps” and the Dutch Nationaal Archief’s presenting “MapIt 1418“, a project to allow users to add suggested locations for their photos in the Flickr Commons!
Tim’s been doing work for The New York Public Library, another Flickr Commons member, and MapWarper (the code that powers the NYPL’s historical map rectifier) is an open source project and available on GitHub.
-
Mikel Maron’s “Free and Open Palestine” (the slides are here but you should really watch the video) which is an amazing story of collecting map data in the West Bank and Gaza.
Mikel was also instrumental in creating a scholarship program to pay the travel and lodging expenses for 15 members from the OSM community, from all over the world, to attend the conference. Because he’s kind of awesome, that way.
But that’s just me. I’d encourage you to spend some time poking around all the other presentations that are available online:
Despite the “bag of tiles” approach for using OSM on Flickr getting a bit old it still works so as of right here, right now:
-
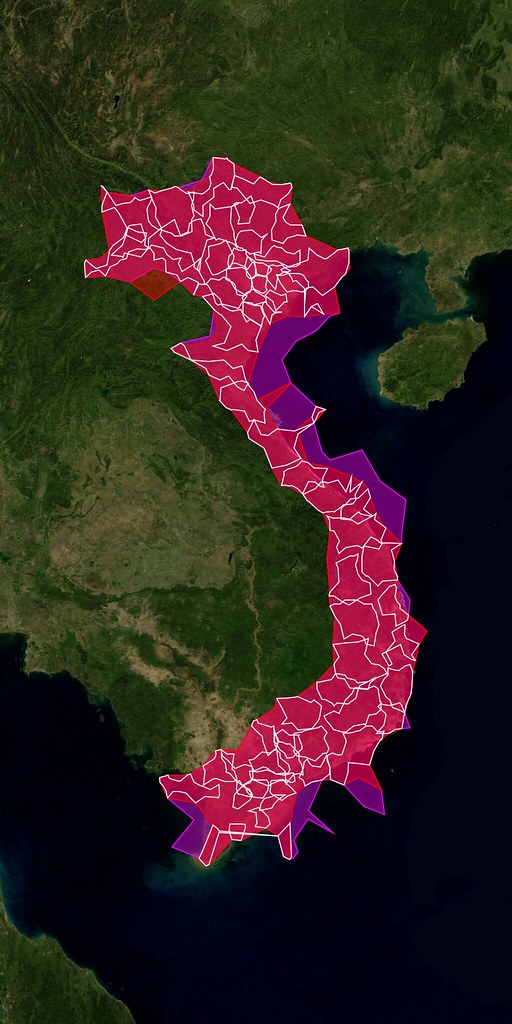
In Vietnam, we’ve added OSM tiles for Ha Noi and Ho Chi Minh City (see also: The State of Vietnam).
-
In Cuba, we’ve added OSM tiles for Havana (see also: The State of Cuba).
-
In Chile, we’ve added OSM tiles for Santiago (if there was a State of Chile presentation I missed it and haven’t found any slides online so instead I’ll just link to this lovely localized version of OSM for Chilean users).
We’ve also refreshed the tiles for Beijing and Tehran where, I’m told, the OSM community has added twice as much data since we first started showing (OSM) maps a month ago!
If it sometimes seems like we’re doing all of this in a bit of an ad hoc fashion that’s because we (mostly) are. How and when and where are all details we need to work out going forward but, in the meantime, we have map tiles where there were none before so it can’t be all bad.
Finally, because the actual decision to attend the conference was so last minute I did not get the memo to all presenters to include a funny picture of SteveC (one of the original founders of Open Street Maps) in their slides.
To make up for that omission, I leave you now with the one-and-only Steve Coast.

Matthias Gansrigler: On flickery, and making your API apps fly
We meant to take a short break in our developer interview series. Well we ended up taking a very long short break. Sorry about that. Thankfully we’re coming back with a really great interview from the developer behind flickery, a full featured, and fast Flickr desktop client. And he is talking about super important topics: optimization, performance and caching.
Part detective story, part day-in-the-life-of-a-working developer, Matthias’ nuts and bolts discussion of how to take full advantage of the Flickr API without slowing down your app is a must read.

Hello there.
My name is Matthias Gansrigler, I’m the founder of Eternal Storms Software, responsible for donationware like GimmeSomeTune or PresentYourApps for Mac.
My newest creation and the reason I’m writing here, however – and first shareware application, might I add – is flickery, a Flickr desktop client for Mac OS X 10.5 Leopard!
With flickery you can easily upload your photos to Flickr, manage your sets and favorites, view your contacts’ photos, search for photos in Flickr’s data, comment, view the most “interesting” pictures and much more. All in one tiny, yet powerful application.
I was kindly invited by the great guys behind Flickr to write about my experiences optimizing calls to the Flickr API.
But first, a little background story:
I was born in 1986 in… well, uhm, that’s maybe a little too far back. Let’s start in 2008. That’s more like it.
In February 2008, I began flirting with the idea of writing a full-featured desktop client for Flickr for Mac. But really, I just wanted to toy around with the Flickr API since I’d seen so many web-applications making use of it and had heard good things of the API in general.
“like a kid in a toys-store”
Soon thereafter, I had tremendous results in the shortest amount of time. I felt like a kid in a toys-store – completely overwhelmed (and way in over my head, as it later turned out). I did not worry very much about how many calls I made to the API. My main interest was in getting a product ready. So it took me about three months (until mid-May 2008) to ship my first public beta. I had implemented lots of things, like commenting on photos, adding photos to favorites, different views of photos, etc. It was a great first public beta, feature-wise. But under the hood, it wasn’t that great. It was sluggish, slow, leaked tons of memory and made an awful lot of calls to the Flickr API. And when I say an awful lot, I mean a hell of a lot. Flickr’s servers were smoking (well, I doubt that, because I think then I would have heard from their lawyers).
“30 QPS”
With just about 1,000 registered users, flickery made more than 30 QPS (queries per second) to the Flickr API. 30 QPS. Can you imagine? How come, you might ask. Just try it, it’s easy (no, seriously, don’t!). I made calls for everything. I even made calls in advance. But let me elaborate.
Take flickery’s main screen. You can see 30 items in the thumbnail view. For every item in that list, I made a getInfo() and getSizes() call for later use (should the user want to view the photo bigger or view it’s description). Additionally, whenever a user selected one of the items, flickery would call out to the API again asking if it was allowed to download that photo. So that’s 1 call for the 30 photos, 30 calls for getInfo and 30 calls for getSizes. That alone is 61 calls for basically ONE user-interaction (clicking on Newest). That’s not right. Should a user go through the entire list and select every item, that’s 30 more calls (totalling at 91). That’s even not righter.
If you want to get your API key shut down (which is what happened to that first public beta of flickery) – that’s absolutely the way to do it. No doubt about it.
Obviously, the really hard work started here – retaining the same feature-set, the same interface and the same comfort, yet making far, far less calls to the API. What also starts here is the really technical gibberish. So get out your nerd-english dictionaries and let’s get to it.
“really hard work”
I basically had all the features in there for a 1.0 release. But I couldn’t release it until it made a proper amount of calls to the API. So where I started, obviously, was at removing the “in-advance” calls to the API, like getInfo and getSizes. They just don’t get called in advance anymore, only on demand. So if a user selects a photo and clicks on “More info”, then the getInfo call is made. No sooner. I chose a different approach for getSizes, which I eliminated entirely (except when downloading a photo). The photo gets loaded in thumbnail-size (which is always there). A double click on the photo loads the medium sized image, which is always there, as well. When you want to view the photo in fullscreen mode, there’s two possibilities. If the call to the API returned a o_dims attribute, we load the original size (since that’s returned in the one call to the API retrieving all the 30 photos). Should there be no such attribute, I just load the medium size and am done with it. So for viewing photos, whatever size, there’s no extra calls made. So from 61 calls, we trimmed that down to 1 call to retrieve the 30 photos. Also, when an item is selected, there is no call made anymore. Only when the user selects “Download”, flickery asks if it is allowed to download that photo and if so, makes a getSizes call to download the largest possible version.
“retrieving the photolist”
Now, for retrieving the photolist. In the first public beta, I made one call for every 30 images I wanted to retrieve. That’s kind of logical. However, that would mean that we would have to make 16 calls to view 480 items. We can trim that down. Flickr allows you to retrieve 500 items at once with each call. So that’s basically what I did. I wrote my own system that internally loaded 480 items, but only returned the 30 items of the page that were requested in the interface. So for viewing 480 photos, we now only need one call, which is like one 16th of the calls we made before. It has a little downside, though – the initial call takes a little longer for results to come back (since it is fetching more items at once from Flickr’s servers). But on the other hand, once those 480 items are retrieved, subsequent paging through those 16 pages is instant.
Adding photos to favorites, sets and groups was the next step. Let’s stay at favorites, because basically, it’s the same procedure for all three of them. In the first public beta, a user could add one photo to their favorites over and over again, and flickery would dutifully send that call to the API. Of course, completely unnecessarily. So I just cached what was added to the favorites and just checked if we already added the photo to the favorites, which, as it turned out, saved lots of highly unnecessary calls.
I also took the liberty to implement some of Flickr’s rules right into flickery, meaning the following: If you’re not the admin of a group, you can only remove your own photos from it. If you’re the admin, you can remove all of them. So instead of flickery making a call to the API when the user wants to remove a photo and they’re not the admin, the application itself tells them they can’t do that. A lot of calls are saved this way.
“caching”
Another big step in making less calls to the API was caching, naturally. In the first public beta, nothing except the frob for talking to the API was saved over application launches. So every time the user launched the application, the authorization token, the Newest photos, the user’s sets and contacts were loaded. All that has changed and they are now saved over restarts for different time intervals. Newest photos for one hour, sets and contacts forever (albeit, the user can reload photosets groups and contacts (once an hour) should they ever be out of sync). The same goes for the contents of photosets, groups, favorites and own photos. To remove some other calls, if there’s a cache already in place for, say, a photoset, I don’t delete that cache should a new photo be added to it, but update it. So, the call is made to the API to add the photo to the set, obviously, but to then view the set (with the newly added photo in it), I don’t reload the photoset but just update the existing cache. Another example here is comments. When adding your own comment to a photo, flickery doesn’t reload the entire comment-list, but just adds the new comment to the already existing cache.
“extras”
Specifying options in the “extras” parameter can save you lots of calls as well. (e.d. see our post on the standard photos response for more on extras) Instead of having to make another call to retrieve certain information about an item, you can have all kinds of information returned in the initial response. Say, you want the owner’s name of items. Instead of having to call flickr.photos.getInfo on every item, you just specify the owner_name option in the “extras” parameter and immediately have the owner’s name for every item of your query. This is really handy and saves lots of time for the users and lots of calls for you.
As for the Flickr API – it’s really great and easy to use. However, there are some smaller things I’d love to see:
Being able to specify more than 1 photoid for adding to / removing from favorites, photosets and groups – resulting in far less calls to the API, the upload response returning not only the photoid for the uploaded image, but also the farm and server, official support for collections, adding / removing contacts, support for retrieving videos, maybe even some calls for flickrMail. Some more “extras” options would be great, too, like can_download, for example, which is currently only retrievable through flickr.photos.getInfo.
Other than that, the Flickr API let’s you really do everything you could imagine. There’s almost no restriction to what you can do with it!
Closing, I’d just like to thank the wizards at Flickr for the opportunity to write about optimizing here and working so closely with me on flickery. Here’s to more great applications using the Flickr API!
extra:extra=extra

Internally, the nomenclature for tags goes something like this: There are “raw” tags (the actual tag you enter on a photo), “clean” tags (the tag that you see in a URL), “machine tags” (things like upcoming:event=2413636) and machine tag “extras”.
Machine tag “extras” are what we call the entire process of using a machine tag as a kind of foreign key to access data stored on another website. Small pieces (of data) loosely joined (by the Internets).
For example if you tagged a photo with upcoming:event=2413636 that would cause a robot squirrel on the Flickr servers to call the robot squirrels running the Upcoming API and ask for the name of the Upcoming event with ID 2413636.
Upcoming then answers back and says: That event was called “Flickr Turns 5.25” and we store the title in our database. The next time you load that photo we’ll show a little Upcoming icon and the name of the event in the sidebar.
To date, we’ve only had machine tags “extras” available for upcoming:event= and lastfm:event= tags but starting today we’re adding support for three new projects: Dopplr, Open Plaques and the Open Library.
dopplr:(eat|stay|explore)=
Dopplr is a social travel site which recently launched a Social Atlas to allow their users to create and share lists of interesting places, in the cities they know about, of where to eat and stay and poke around during their visit.
“Over time, we can anonymise and aggregate all the recommendations that have been added to Dopplr. This is the Social Atlas itself, something that’s greater than the sum of its parts: a kind of world map representing the combined wisdom of smart travellers. It’s early days still, but we are very excited by its potential.”
Which is pretty exciting, especially when you think about how many pictures of delicious food people upload to Flickr!

You can add Social Atlas machine tags to your photos by tagging them with either "dopplr:eat=", "dopplr:stay=" or "dopplr:explore=" followed by the short-code for that place.
For example, dopplr:eat=tp71.

As an added bonus every single page in the Dopplr Social Atlas displays the complete machine tag you need to tag your photos with so you can just copy and paste the tag from one page into the other and your photos will be updated like magic!
openplaques:id=
The Open Plaques website is a community-run website set up to catalogue and document the many blue plaques that are hung across the UK to commemorate persons and famous events.
Frankie Roberto, one of the people behind the project has written often about the project, and the motivations behind it so rather than try to paraphrase I will just quote him (at length):
“With these in mind, I was thinking how this kind of ‘mobile learning’ might apply to the heritage sector, and as you might have guessed from the title, thought of blue plaques. You see them everywhere — especially when sat on the top deck of a double decker bus in London — and yet the plaques themselves never seem that revealing. You’ve often never heard of the person named, or perhaps only vaguely, and the only clue you’re given is something like “scientist and electrical engineer” (Sir Ambrose Fleming) or “landscape gardener” (Charles Bridgeman). I always want to know more. Who are these people, what’s the story about them, and why are they considered important enough for their home to be commemorated?”
— Getting information about blue plaques on your mobile phone…

“The final step towards making this more compelling was to add some photographs. Here, Flickr came to our rescue. There was already a ‘blue plaques’ group, which contained hundreds of photos. To link them together, I used special tags called ‘machine tags’, which are like normal tags except that they contain some slightly more structured data. It’s very simple though — each plaque on the Open Plaques website has an ID number (which can be found at the end of the URL), and the corresponding machine tag for that plaque is openplaques:id=999 (where 999 is the ID number). Another script then uses the Flickr API to find all the photos tagged with a relevant machine tag, checks to see if they are Creative Commons licenced, and then to displays them on the Open Plaques website, with a credit and a link back to the Flickr photo page.”
So, we did the same! If you have an openplaques:id= machine tag on your photo then we’ll try to look up and display the inscription for that plaque.
You can add Open Plaques machine tags to your photos by tagging them with "openplaques:id=" followed by the numeric ID for a specific plaque.
For example, openplaques:id=1633.
openlibrary:id=
The Open Library is a part of the Internet Archive whose mission is to create a “web page for every book ever published.” To do that they’re hoping that anyone and everyone will participate and help by adding information they have a published work or a particular edition.
“After almost fifty years of computerizing everything, we’re realising now that the stories have gone, and we need them back — the handicraft, the boutique, the beauty, the dragons, the colour of stories. I’m reminded of the gorgeous mysterious early maps of the Australian coast. The explorer only got so far, and the cartographer could only draw so much. Much more exciting than boring old satellite, top-of-a-pin’s-head accuracy! I love the idea of trying to catch some of these dog-eared tales within Open Library.”
As it happens Flickr users have created over 900 groups about book covers and a casual search for the phrase (“book covers”) returns 98, 000 photos!
Back in July of 2007 Johnson Cameraface uploaded a photo of the cover of ROBOTS Spaceships & Other Tin Toys”. Two years later, George asked if it would be alright to use the photo to update the Open Library record for the book, and added an openlibrary machine tag along the way.
Now, starting today, the photo page now displays the title of the book and links back to the Open Library!

This makes me happy.
You can add Open Library machine tags to your photos by tagging them with "openlibrary:id=" followed by the unique identifier for that book.
For example, openlibrary:id=OL5853184M.
It’s worth noting that the unique identifiers for Open Library books are sometimes a bit of a treasure hunt; they are the letters and numbers that come after openlibrary.org/b/ and before the book title in the URL for that book. Like this:
http://openlibrary.org/b/OL5853184M/Soviet-science-fiction
But wait! There’s more!!

Did I mention that we have over one million photos tagged with Last.fm event machine tags? That makes it kind of hard to know when new machine tags have been added because lopping over all those tags just to find recent ones is expensive and time-consuming.
To help address this problem we’ve add a shiney new API method called:
flickr.machinetags.getRecentValues
This does pretty much what it sounds like. Given a namespace or a predicate (or both) and a Unix timestamp, the method returns the values for those machine tags that have been added since the date specified.
Enjoy!
Twitter in the API

Ever since we launched our Flickr2Twitter beta, developers have been requesting new API methods, so they can support Flickr as a photo sharing option in their Twitter clients.
I’ve got good news, and bad news.
The bad news is we don’t have any new APIs to offer you.
The good news is we shipped our “Twitter APIs” nearly five years ago.
Let me explain.
Working with Blogs (including Twitter)
For as long as anyone can remember, we’ve supported the option of posting to external blogs directly from Flickr. Once you’ve configured a blogging service it becomes available in the “Blog This” drop down, as an option for Upload by Email, and, of course, in the API.
You and I might have serious philosophical questions about whether Twitter is a blogging service, but our web servers are more pragmatic. To them, the Twitter integration is just a new blogging service.
Configuring a blogging service
The first step for a member wishing to blog (or tweet) via Flickr is to configure an external blog. The only way to do this on flickr.com, generally from the Add a blog page.
Twitter is a bit special (or rather a preview of things to come) as we’ve given it its own service page. Directing users of your app to the Flickr2Twitter page is probably the best way get them “tweet ready”.
All set?

From here on out, you’ll need your user to have authorized you to access their Flickr account. (Find out more about FlickrAuth)
With a signed call to flickr.blogs.getList() you can get a list of all the blogging services a member has configured. Alternately you can pass in a service id (e.g. Twitter) to scope the list of blogs to the service you’re interested in. The response looks something like:
<blogs>
<blog id="7214" name="Code Flickr" service="MetaWeblogAPI" needspassword="0" url="http://code.flickr.com/blog/"/>
<blog id="7215" name="Twitter: kellan" service="Twitter" needspassword="0" url="http://twitter.com/kellan"/>
<blog id="72157" name="Twitter: Flickr" service="Twitter" needspassword="0" url="http://twitter.com/flickr"/>
</blogs>
This account has 3 blogs configured. A WordPress blog, and two Twitter accounts. Each one has a unique id. Additionally needpassword="0" means we have credentials for these blogs stored server side and you don’t need to prompt your user to log in to their blog.
If you passed in Twitter as the service, and instead of the above you got something like:
<blogs/>
Then your user hasn’t configured any blogs for that service.
The Easy Option: Upload a photo to Flickr, post to Twitter via Flickr
If your application has been authorized to upload photos on your user’s behalf, and you’ve made sure they have a Twitter blog configured with Flickr, then the easiest solution is to use Flickr as a passthru service.
Once you’ve successfully uploaded a photo you’ll get an API response like <photoid>1234</photoid>. (Find out more about uploading and asynchronous uploading).
Pass the blog id from the <blogs> list above, and the photoid from the upload response to flickr.blogs.postPhoto(). If you’re posting to Twitter the title argument is optional and the description argument is ignored. (By default the title of the photo is the body of the tweet, alternately pass a different status update in the title field)
Or instead of passing a blog id, you can pass a service id (i.e. Twitter) and the photo (and blog post) will be sent to the first matching blog of that service. If we don’t find a blog matching that service, you’ll get a “Blog not found.” error.
Assuming your API call to flickr.blogs.postPhoto() is well formed, Flickr will turn around and post your user’s tweet to Twitter, including a short flic.kr url linking back to their photo.

The Established Option: Upload a photo Flickr, post to Twitter any which way you can
If you’re looking to integrate Flickr photos into an existing Twitter application you might already have a preferred method for posting to Twitter.
After you’ve successfully uploaded a photo and received the photoid follow these instructions for manufacturing a short url using the flic.kr domain.
Unlike most URL shortening schemes, every photo on Flickr already has a short URL associated with it. The follow the form:
http://flic.kr/p/{base58-photo-id}
By the way, you shouldn’t feel constrained to only use short urls on Twitter. They work equally well for a diverse range of applications including fortune cookies.
Thumbnails
If you want to display a thumbnail of a photo, you’ll need to make an API call to one of the methods that returns the photo’s secret. Either flickr.photos.getSizes() or flickr.photos.getInfo() will do. Read up on constructing Flickr URLs.
Follow Along
My favorite new game has been watching the flows of shared Flickr photos as they appear on Twitter.
Happy photo sharing!
Slides from Velocity 2009
At Flickr Engineering our favorite thing is rainbows. But fast stable websites come a pretty close second. So last week some of us drove down to San Jose to take part in the 2009 O’Reilly Velocity conference.

The conference consists of two tracks, performance and operations. The attendance was a great mix of people working on optimizing the whole web stack – everything from the download size of CSS to the PUE of data centers. There were talks on automated infrastructure, Javascript, MySQL, front-end performance recommendations and CDNs, but the most significant theme was the direct business benefits that companies like Google and Microsoft are seeing from microsecond speed improvements on their sites.
Some of the most interesting sessions for for us were:
- John Adams talking about Twitter operations (details , slides , video )
- Eric Schurman and Jake Brutlag’s joint presentation about performance benefits seen at Google and Bing (details , slides , video )
- Andrew Shafer’s discussion of Agile Infrastructure (details )
- Adam Jacobs and Ezra Zygmuntowicz’s talk about Cloud Infrastructure (details )
John and I also gave a talk on how Flickr’s engineering and operations team work together to allow us to iterate quickly without causing stability problems. The full video is available, and here’s the slides:
Thank you to Jesse and Steve for putting together a great conference. We’re already looking forward to next year.
Every Step A Story

Many of you will have already read on the sister Flickr.com blog that we added “nearby” pages to the m.flickr.com site, last week, for phones that support the W3C Geolocation API (that means the iPhone, or Gears if you’ve got an Android phone).
Ross summed it up nicely, writing:
Use this to explore your neighborhood, or find the best places to photograph local landmarks from. Reload the page as you walk around a city, and see the things that have happened there in the past. You’ll see a place through the eyes of the flickrverse.
We’ve also updated the nearby pages on the main site so that when you go to…
…without a trailing latitude and longitude, we’ll see if you have any one of a variety of browser plugins that can tell us your location. This is similar to the Find My Location button on the site maps, that Dan described back in April, but for nearby!
Like the iPhone’s Mobile Safari browser, the next version of Firefox (version 3.5, currently being tested as a release candidate) will also support automagic geolocation so you won’t even need to install any plugins or other widgets.
Just point your browser to www.flickr.com/nearby/ and away you go.

The other piece of nearby-related news is Tom Taylor’s fantastic FireEagle application for the Mac called Clarke.
Clarke is a toolbar app that sits quietly in the background and scans the available wireless networks using the Skyhook APIs to triangulate your position and updates FireEagle with your current location.
In addition to being an excellent FireEagle client, Clarke also supports Nearby-iness for a variety of services, including Flickr.

I’m writing this post from FlickrHQ, in downtown San Francisco, so when I choose Flickr from Clarke’s Nearby menu it loads the following page in my web browser:
http://www.flickr.com/nearby/37.794116,-122.402776
Which is kind of awesome! It means that you can travel to a brand new place, open up your laptop and just like magic (read: once you’ve connected to a wireless network) see pictures nearby.
Woosh!
Flickr Shapefiles Public Dataset 1.0
The name sort of says it all, really, but here’s the short version:
We are releasing all of the Flickr shapefiles as a single download, available for use under the Creative Commons Zero Waiver. That’s fancy-talk for “public domain”.
The long version is:
To the extent possible under law, Flickr has waived all copyright and related or neighboring rights to the “Flickr Shapefiles Public Dataset, Version 1.0”. This work is published from the United States. While you are under no obligation to do so, wherever possible it would be extra-super-duper-awesome if you would attribute flickr.com when using the dataset. Thanks!
We are doing this for a few reasons.
- We want people (developers, researchers and anyone else who wants to play) to find new and interesting ways to use the shapefiles and we recognize that, in many cases, this means having access to the entire dataset.
- We want people to feel both comfortable and confident using this data in their projects and so we opted for a public domain license so no one would have to spend their time wondering about the issue of licensing. We also think the work that the Creative Commons crew is doing is valuable and important and so we chose to release the shapefiles under the CC0 waiver as a show of support.
- We want people to create their own shapefiles and to share them so that other people (including us!) can find interesting ways to use them. We’re pretty sure there’s something to this “shapefile stuff” even if we can’t always put our finger on it so if publishing the dataset will encourage others to do the same then we’re happy to do so.

The dataset itself is pretty straightforward. It is a single 549MB XML file uncompressed (84MB when zipped). The data model is a simple, pared-down version of what you can already get via the Flickr API with an emphasis on the shape data.
Everything lives under a single root places element. For example:
<place woe_id="26" place_id="BvYpo7abBw" place_type="locality" place_type_id="7" label="Arvida, Quebec, Canada"> <shape created="1226804891" alpha="0.00015" points="45" edges="15" is_donuthole="0"> <polylines bbox="48.399932861328,-71.214576721191,48.444801330566,-71.157333374023"> <polyline> <!-- points go here--> </polyline> </polylines> <shapefile url="http://farm4.static.flickr.com/3203/shapefiles/26_20081116_082a565562.tar.gz" /> </shape> <!-- and so on --> </place>
Aside from the quirkiness of the shapes themselves, it is worth remembering that some of them may just be wrong. We work pretty hard to prevent Undue Wronginess ™ from occurring but we’ve seen it happen in the past and so it would be, well, wrong not to acknowledge the possibility. On the other hand we don’t think we would have gotten this far if it wasn’t mostly right but if you see something that looks weird, please let us know
The dataset is available for download, today, from:
http://www.flickr.com/services/shapefiles/1.0/
The other exciting piece of news is that the Yahoo! GeoPlanet team has also released a public dataset of all their WOE IDs that include parent IDs, adjacent IDs and aliases (that’s just more fancy-talk for “different names for the same place”) under the Creative Commons Attribution License.
Which is pretty awesome, really.

They’ve also released the GeoPlanet Placemaker API. You feed it a big old chunk of free-form text and then “the service identifies places mentioned in text, disambiguates those places, and returns unique identifiers (WOEIDs) for each, as well as information about how many times the place was found in the text, and where in the text it was found.”
Again, Moar Awesome.
And a bit dorky. It’s true. The data, all by itself, won’t tell a story. It needs people and history to make that possible but as you poke around all this stuff don’t forget the value of having a big giant, and now open, database of unique identifiers and what is possible when you use them as a bridge between other things. Without WOE IDs we wouldn’t have been able to generate the shapefiles or do the Places project or provide a way to search for photos by place, rather than location.
Enjoy!
Oh, and those “unidentified” outliers, in New York City, that I mentioned in the last post about the donut hole shapefiles: The Bronx Zoo, Coney Island and Shea Stadium. Of course!
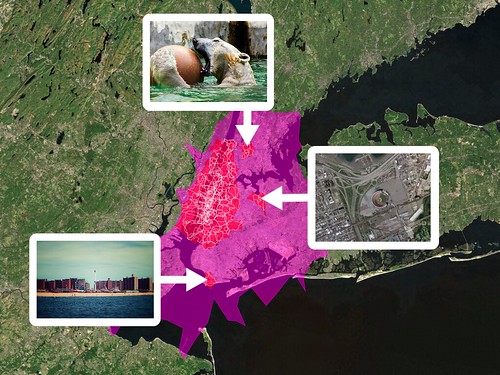
The Absence and the Anchor

Back in January, I wrote a blog post about some experimental work that I’d been doing with the shapefile data we derive from geotagged photos. I was investigating the idea of generating shapefiles for a given location using not the photos associated with that place but, instead, from the photos associated with the children of that place. For example, London:
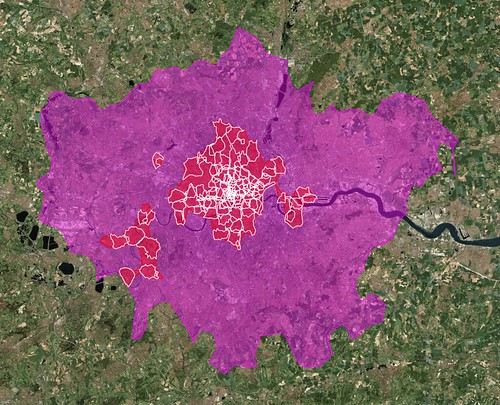
The larger pink shape is what we (Flickr) think of as the “city” of London. The smaller white shapes are its neighbourhoods. The red shapes represent an entirely new shapefile that we created by collecting all the points for those neighbourhoods and running them through Clustr, the tool we use to generate shapes.
For lack of any better name I called these shapes “donut holes” because, well, because that’s what they look like. The larger shape is a pretty accurate reflection of the greater metropolitain area of London, the place that has grown and evolved over the years out of the city center that most people would recognize in the smaller red shape. Our goal with the shapefiles has always been to use them to better reverse-geocode people’s geotagged photos so these sorts of variations on a theme can better help us understand where a place is.
Like New York City. No one gets New York right including us try as we might (though, in fairness, it’s gotten better recently (no, really)) and even I am hard pressed to explain the giant pink blob, below, that is supposed to be New York City. On the other hand, the red donut hole shape even though (perhaps, because) it spills in to New Jersey a bit is actually a pretty good reflection of the way people move through the city as a whole.
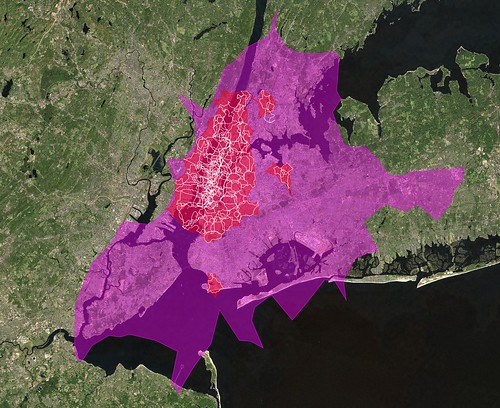
It could play New York on TV, I think.
I’m not sure how to explain the outliers yet, either, other than to say the shapefiles for city-derived donut holes may contain up to 3 polygons (or “records” in proper Shapefile-speak) compared to a single polygon for plain-old city shapes so if nothing else it’s an indicator of where people are taking photos.
If the shapefiles themselves are uncharted territory, the donut holes are the fuzzy horizon even further off in the distance. We’re not really sure where this will take us but we’re pretty sure there’s something to it all so we’re eager to share it with people and see what they can make of it too.
(This is probably still my favourite shapefile ever.)
Starting today, the donut hole shapes are available for developers to use with their developer magic via the Flickr API.
At the moment we are only rendering donut hole shapefiles for cities and countries. I suppose it might make sense to do the same for continents but we probably won’t render states (or provinces) simply because there is too much empty unphotographed space between the cities to make it very interesting.
There are also relatively few donut holes compared to the corpus of all the available shapefiles so rather than create an entirely new API method we’ve included them in the flickr.places.getShapeHistory API method which returns all the shapefiles ever created for a place. Each shape element now contains an is_donuthole attribute. Here’s what it looks like for London:
<shapes total="6" woe_id="44418" place_id=".2P4je.dBZgMyQ" place_type="locality" place_type_id="7"> <shape created="1241477118" alpha="9.765625E-05" count_points="275464" count_edges="333" is_donuthole="1"> <!-- shape data goes here... --> </shape> <!-- and so on -> </shapes>
Meanwhile, the places.getInfo API method has been updated to included a has_donuthole attribute, to help people decide whether it’s worth calling the getShapeHistory method or not. Again, using London as the example:
<place place_id=".2P4je.dBZgMyQ" woeid="44418" latitude="51.506"
longitude="-0.127" place_url="/United+Kingdom/England/London"
place_type="locality" place_type_id="7" timezone="Europe/London"
name="London, England, United Kingdom" has_shapedata="1">
<shapedata created="1239037710" alpha="0.00029296875" count_points="406594"
count_edges="231" has_donuthole="1" is_donuthole="0">
<!-- and so on -->
</place>
Finally, here’s another picture by Shannon Rankin mostly just because I like her work so much. Enjoy!

What Would Brooklyn Do?

The other day, Mike Ellis posted a really lovely interview with Shelley Bernstein and Paul Beaudoin about the release of the Brooklyn Museum’s Collections API.
One passage that I thought was worth calling out, and which I’ve copied verbatim below, is Shelley’s answer to the question “Why did you decide to build an API?”
First, practical… in the past we’d been asked to be a part of larger projects where institutions were trying to aggregate data across many collections (like d*hub). At the time, we couldn’t justify allocating the time to provide data sets which would become stale as fast as we could turn over the data. By developing the API, we can create this one thing that will work for many people so it no longer become a project every time we are asked to take part.
Second, community… the developer community is not one we’d worked with before. We’d recently had exposure to the indicommons community at the Flickr Commons and had seen developers like David Wilkinson do some great things with our data there. It’s been a very positive experience and one we wanted to carry forward (emphasis mine) into our Collection, not just the materials we are posting to The Commons.
Third, community+practical… I think we needed to recognize that ideas about our data can come from anywhere, and encourage outside partnerships. We should recognize that programmers from outside the organization will have skills and ideas that we don’t have internally and encourage everyone to use them with our data if they want to. When they do, we want to make sure we get them the credit they deserve by pointing our visitors to their sites so they get some exposure for their efforts.
The only thing I would add is: What she said!
Kittens vs Sunsets
Speaking of things that Kellan has done recently, Jayel over in this thread: Flickr Trends Search kicked off a whole Flickr Central thread of This vs That …

… including Girls vs Boys, Mayonnaise vs. Ketchup, Winter vs Summer and Varying vs Flatlined.
Why not go and have a play?
As the footer says “derived from the awesome NYT Trender and code by derekg
adapted for Flickr API by kellan”