Over on our sister photo arty blog you could easily imagine reading phrases like “One of the amazing things about working at Flickr is the vast amount of incredible photography it exposes you to“, or some such. Hah! Those arty types!
Over here, I’d like to post the flip side … about how one of the amazing things about working at Flickr, is the awesome people I get to work with.

Take for example …
Ross Harmes
… people often think I’m joking when we’re sitting in a meeting, discussing how we should standardise our front-end coding conventions or some such and I say we should just “ask Ross”.
But! BUT!! but, Ross wrote a fricking book about JavaScript; Pro JavaScript Design Patterns and sits 3 desks away, it’s faster (and more amusing (to me)) to shout out a question than it is to flick through the index of the book. It’s like having the talking Kindle version, but with a much more natural voice!
You can also find out more at jsdesignpatterns.com
Anyway …
The reason why I wanted to post this, is that recently an awful lot of my co-workers have been doing stuff! So with an eye to that …
The Lovely Kellan Elliott-McCrea
Flashing quickly across the radar last couple of weeks is/was a bunch of discussion about URL shorteners, sort of starting with Josh over here: on url shorteners, and David with The Security Implications of URL Shortening Services. With other discussions popping up here and there and sorta everywhere.
And so, with this bit of philosophy from “Stinky” Willison (more on Simon later) …

… Kellan built this (maybe even during meetings); RevCanonical: url shortening that doesn’t hurt the internet, you can read more about it in his blog post URL Shortening Hinting [Note: includes mention of Flickr], where the comments are worth price of admission alone, also, features hamster photos.
If you want to join in, you can read more over on the official RevCanonical blog and get, fork or whatever it is people do with code on github. And I’m sure we’ll have more news about RevCanonical here soon :)
But not content with starting that wildfire, Kellan has also been does his bit to help OpenStreetMap, by walking around with a GPS unit and, I think this part is important, drinking beer …

… shown here featuring our good friend Mikel Maron, remember we use OpenSteetMap on Flickr when our own maps are a little sparse. More on maps later!
Meanwhile …
The Mighty John Allspaw
Mr Allspaw is our wonderful Ops guy, here he is …

… smoldering.
As well as smoldering he also gave a talk at the Web 2.0 Expo called Operational Efficiency Hacks the other week. If you’re into that type of thing and missed it, which you probably did, here are his slides …
… and his follow up post adds a little further reading. If you like this kinda of thing you should probably subscribe to his blog where he posts really interesting Flickr related stuff, and infuriatingly enough *not* here on this blog, /me sulk.
On the subject of Allspaw (and as we’ve already mentioned one book), I was pretty sure I’d mentioned his book before: The Art of Capacity Planning: Scaling Web Resources … if building big things on the web is your kinda thing, but apparently I haven’t, so …
According to a reviewer on Amazon “John’s examples are just like Charlie’s from the TV show Numb3rs”, having never watched Numb3rs I can only assume that’s a probably a bad thing (kinda like Scully from X-Files explaining science) but gave it 4 stars anyway :) on those grounds alone you should buy it …

Oh and don’t forget the WebOps Visualizations Pool on flickr, that John often posts to when things suddenly get much better or worse ;) if you enjoy graphs like this …

Getting back to the front-end for a second …
Scott Schiller, Fish enthusiast!
You’ve heard of Muxtape right? That website that plays MP3s, how’d you think it does that? Or the cool javascript/audio stuff that Jacob Seidelin does over at Nihilogic; JavaScript + Canvas + SM2 + MilkDrop = JuicyDrop & Music visualization with Canvas and SoundManager2?
Screenshot shown here (warning: link to noisy thing) …
![A [ Radiohead / JavaScript / Boids / Canvas / SM2 ] mashup by Jacob Seidelin](http://farm4.static.flickr.com/3305/3427837146_6ddf2b3870.jpg)
Well they both use SoundManager 2 written by our very own Scott Schiller.
It’s an extensive and easy to use javascript thingy … wait, Scott says it better … “SoundManager 2 wraps and extends the Flash Sound API, and exposes it to Javascript. (The flash portion is hidden, transparent to both developers and end users.)” … which basically means that if you like JavaScript, messing with audio but hate, I mean, dislike working with Flash, it can save you a lot of pain. Here’s one of the demos Scott put together …
And if you think that all looks awesome, remember that Scott is one of our fantastic front-end guys, bringing all that good js magic to Flickr! Apart from the music part, well unless we one day decide to add music and customisable backgrounds to flickr [1].
Aaron Straup Cope
Aaron covered this only the other day: The Only Question Left Is, but has been doing an awful lot with generating shapefiles recently. I just wanted to add my take to it, because even I have trouble keeping up.
Basically what I want, is to be able to send something-somewhere a list of latitudes and longitudes and it return me the “shape” that those points make. This could be anything, the locations of geotagged Squirrels, or even something useful, well kinda like this from Matt Biddulph (him wot of Dopplr) …
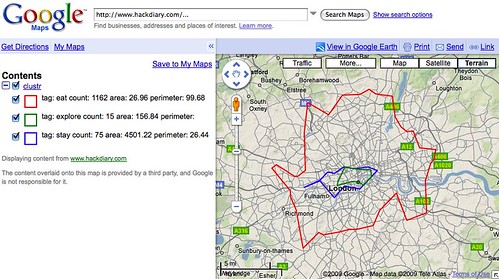
“London dopplr places, filtered to only places my social network has been to, clustrd“
… which maps out something of interest to him, where his “social network” go/eat etc. in London. Which may be different from mine, or could even have some overlap, thus answering the time old question; which pub should we all go to for lunch?
It’s not quite at the point where you can do it without having to put a little effort in, but I keep prodding Aaron because I want it now! But if you’re the type that does enjoy putting the effort in then you can again do the GitHub dance here: ws-clustr and py-wsclustr (Python bindings for spinning up and using an EC2 instance running ws-clustr).
Once more, more on maps later.
Daniel Bogan – Setup Man
Bogan is virtual, and only exists in the internets, as can be seen here …

… kind of like Max Headroom, but with worse resolution. Which I think makes Flickr the first interweb company you have a real AI working on the code, not that pretend AI stuff!
Last year he has a bash at helping to put a little context around us delicate flower developers, with a quick run-down of the setup we each used with Trickr, or Humanising the Developers (Part 1) & Trickr, or Humanising the Developers (Part 2). Based on an old project of his called “The Setup” where he used to interview various Internet Famous people (when there wasn’t so damn many of them) about their Setup.
Recently he’s reprised that task, with, wait for it … The Setup, where our very own Bogan asks such leading lights as John Gruber, Steph Thirion, Jonathan Coulton & Gina Trapani. I have no idea how he finds the time!
In turn you can read a quick interview with Bogan over at indicommons.
Rev Dan Catt — errr, me!
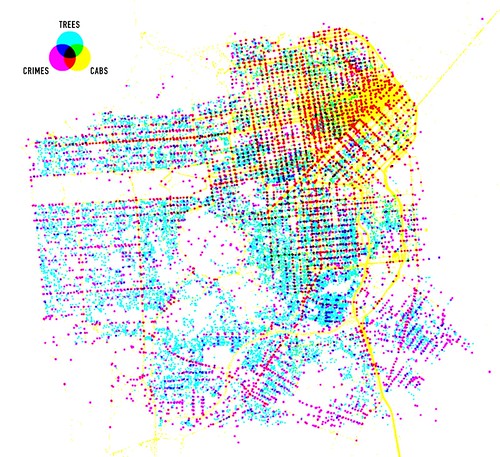
Meanwhile, if you’re reading this blog, you’ve probably already seen this, I’ve been trying my hand at using Processing to visualize 24 hours of geotagged photos on Flickr …
… which I managed by following the instructions here Processing, JSON & The New York Times to get Processing to consume our very own Flickr API in JSON format. Which in turn started me off prodding at the Processing group …

and Visualization groups on Flickr …
Pulling it all together
So that’s what some of us are up-to, and going back to the start, I’m amazed and all the stuff that goes on, brilliant minds and all that.
In my head, this is what ties it all together, hang on, here we go …
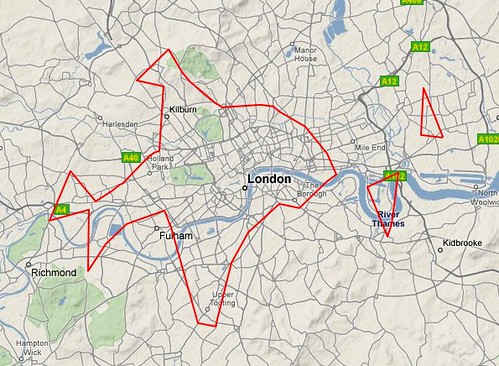
Kellan’s been walking around with a GPS unit (along with 1000s of others), adding to the OpenStreetMap (OSM) dataset, we (Flickr) sometimes use that dataset, but also … Matt Jones (also him wot of Dopplr) made this …

… using Cloudmade, who in turn use OSM data to allow people to easily style up and use maps. Now, I’m sure Mr Jones, wont mind me saying that he’s not a coder, infact here he is; Matt Jones – Design Husband …

… but a non-programmer can now easily make maps, as demonstrated above and described here: My first Cloudmade map style: “Lynchian_Mid”.
Then using our wonderfully public Shape Files API (flickr.places.getShapeHistory which yes you can get in JSON format for using with Processing or JavaScript) overlay boundaries. Even, when it’s easier (for the non-programmer) plot outlines and shapes, based on the code Aaron is working on, onto those maps.
More on making maps here: maps from scratch.
But where could you get such useful data for plotting or visualising, well obviously there’s our API, which is where the senseable team at MIT got the data for their Los ojos del mundo (the world’s eyes) project, again using Processing …
(un)photographed Spain from senseablecity on Vimeo.
But also, let us recall “Stinky” Willison, one time employee of Flickr, who now works at The Gruadian. They have a geocoding project, that allows you, if you so wished to place their stories on a map … http://guardian.apimaps.org/search.html … which uses Mapping from Cloudmade, map data from OpenStreetMap, location search from our very own API, and stories from their own API. Which in turn allows you to plot their stories on your own maps, phew!
More about the Guardian Open Platform.

You can also read about their Data Store, which gives you access to a load of easy to use data just ripe for visualizing…
… be that with Processing, Flash or JavaScript (following the advice in Ross’s book), and even with photos from Flickr and Audio driven with Scott’s SoundManager2, in “Shapes” powered by Aaron, and preserved with short URLs that’ll stick around, thanks Kellan :) and you can scale it if you need to by following John’s insights.
And that’s just what we do when we’re not working on Flickr.
Photos by Ross Harmes, Kellan, jspaw, jesse robbins, Matt Biddulph, waferbaby, moleitau and dan taylor.
[1]never going to happen.