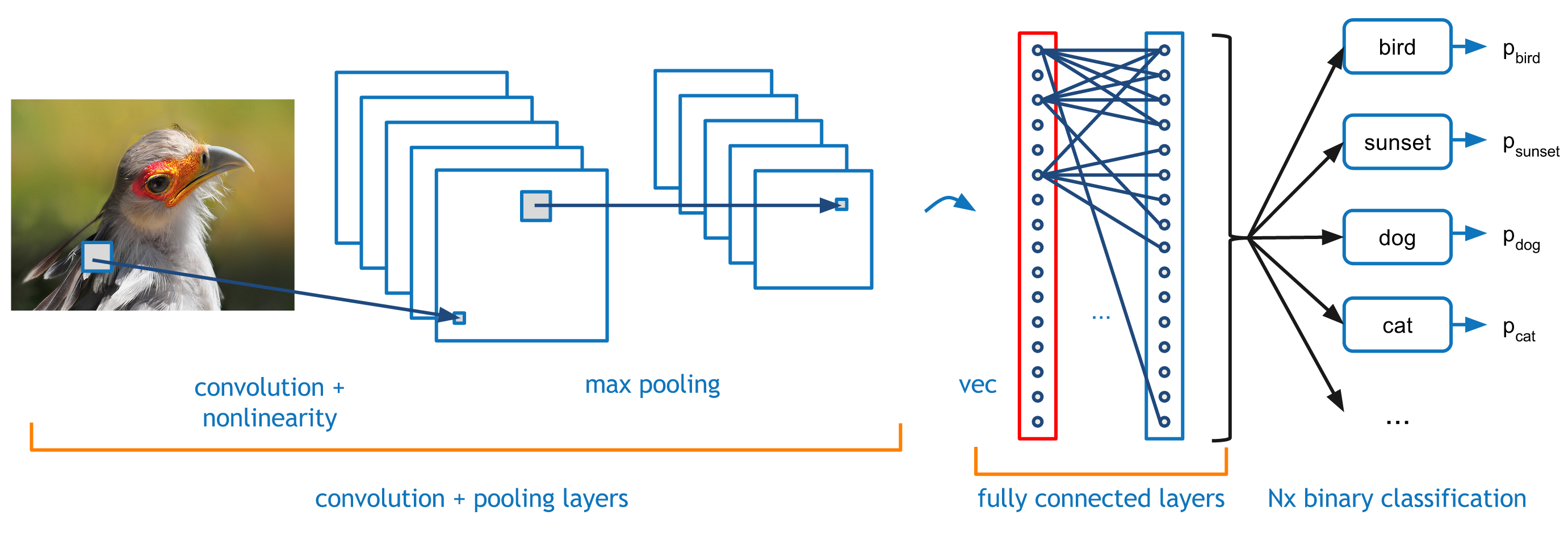
One of the goals of our recently launched (and awesome!) new Flickr iPhone app was to further increase user engagement on Flickr. One of the best ways to drive engagement is to make sure Flickr users know what’s happening on Flickr in as near-real time as possible. We already have email notifications, but email is no longer a good mechanism for real-time updates. Users may have many email accounts and may not check in frequently causing timeliness to go right out the window. Clearly this called for… PUSH NOTIFICATIONS!

Motor bike racer getting a push start at the track, Brisbane by State Library of Queensland, Australia
I know, you’re thinking, “anyone can build push notifications, we’ve been doing it since 2009!” Which is, of course, absolutely true. The process for delivering push notifications is well trod territory by this point. So… let’s just skip all that boring stuff and focus on how we decided on the underlying architecture for our implementation. Our decisions focused on four major factors:
- Impact to normal page serving times should be minimal
- Delivery should be in near-real time
- Handle thousands of notifications per second
- The underlying services should be highly available
Baby Steps
Given these goals, we started by looking at systems we already have in place. Everyone loves not writing new code, right? Our thoughts immediately went to Flickr’s existing PuSH infrastructure. Our PuSH implementation is a great way to get an overview of relevant activity on Flickr, but it has limitations that made it unsuitable for powering mobile push notifications. The primary concern is that it’s less-near-real time than we’d like it to be. On average, activities occurring on Flickr will be delivered to a subscribed PuSH endpoint within one minute. That’s certainly better than waiting for an email to arrive or waiting until the next time you log in to the site and see your activity feed, but it’s not good enough for mobile notifications! This delay is due to some design decisions at the core of the PuSH system. PuSH is designed to aggregate activity and deliver a periodic digest and, because of this, it has a built in window to allow multiple changes to the same photo to be accumulated. PuSH is also focused on ensured delivery, so it maintains an up to date list of all subscribers. These features, which make PuSH great for the purpose it was designed, make it not-so-great for real time notifications. So, repurposing the PuSH code for reuse in a more real time fashion proved to be untenable.
Tentative Plans
So, what to do? In the end we wound up building a new lightweight event system that is broken up into three phases:
- Event Generation
- Event Targeting
- Message Delivery
Event Generation
The event generation phase happens while processing the response to a user request. As such, we wanted to ensure that there was little to no impact on the response times as a result. To ensure this was the case, all we do here is a lightweight write into a global Redis queue. We store the minimum amount of data possible, just a few identifiers, so we don’t have to make any extra DB calls and slow down the response just to (potentially) kick off a push notification. Everything after this initial Redis action is processed out of band by our deferred task system and has no impact on site performance.
Event Targeting
Next in the process is the event targeting phase. Here we have many workers reading from the global Redis queue. When a worker receives an event from the queue it rehydrates the data and loads up any additional information necessary to act on the notification. This includes checking to see what users should be notified, whether those users have devices that are registered to receive notifications, if they’ve opted out of notifications of this type, and finally if they’ve muted activity for the object in question.
Message Delivery
Flickr’s web-serving stack is PHP, and, up until now, everything described has been processed by PHP. Unfortunately, one area where PHP does not excel is long-lived processes or network connections, both of which make delivering push notifications in real time much easier. Because of this we decided to build the final phase, message delivery, as a separate endpoint in Node.js.
So, the question arose: how do we get messages pending delivery from these PHP workers over to the Node.js endpoints that will actually deliver them? For this, we again turned to Redis, this time using its built in pub/sub functionality. The PHP workers simply publish a message to a Redis channel with the assumption that there’s a Node.js process subscribed to that channel eagerly awaiting some data on which it can act.
After that the Node process delivers the notification to Apple’s APNS push notification system. Communicating with APNS is a well-documented topic, and not one that’s particularly interesting. In fact, I can sum it up with a single link: https://github.com/argon/node-apn, a great npm package for talking to APNS.
The Real Challenge
There is, however, a much more interesting problem to discuss at this point: how do we ensure that delivery to APNS is both scalable and highly available? At first blush, this seems like it could be problematic. What if the Node.js worker has crashed? The message will just be lost to the ether! Solving this problem turned out to be the majority of the work involved in implementing push notifications.
Scalability
The first step to ensuring a service is scalable is to divide the workload. Since Node.js is single threaded, we would already be dividing the workload across individual Node.js processes anyway, so this works out well! When we publish messages to the Redis pub/sub channel, we simply publish to a sharded channel. Each Node.js process subscribes to some subset of those sharded channels, and so will only act on that subset of messages.
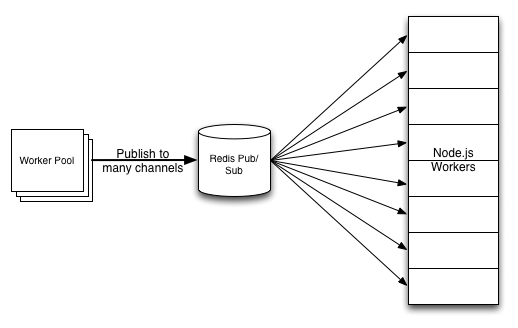
Configuring our Node.js processes in this way makes it easy to scale horizontally. Whenever we need to add more processing power to the cluster, we can just add more servers and more shards. This also makes it easy to pull hosts out of rotation for maintenance without impacting message delivery: we simply reconfigure the remaining processes to subscribe to additional channels to pick up the slack.
Availability
Designing for high availability proved to be somewhat more challenging. We needed to ensure that we could lose individual Node processes, a whole server or even an entire data center without degrading our ability to deliver messages. And we wanted to avoid the need for a human in the loop — automatic failover.
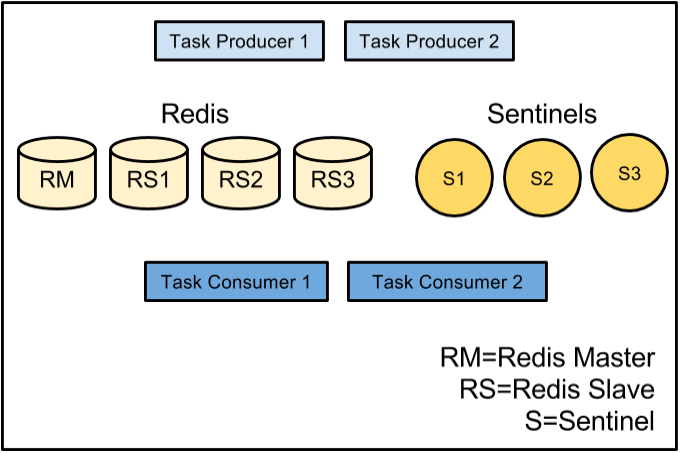
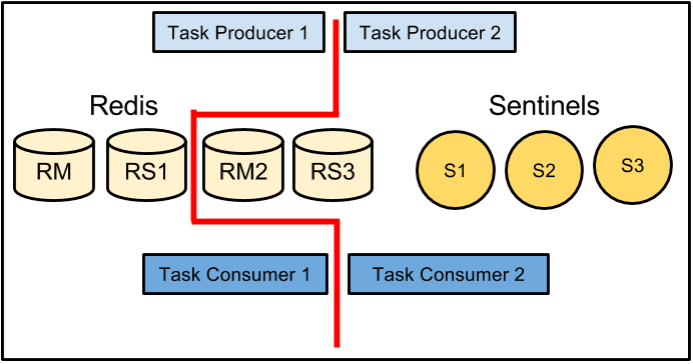
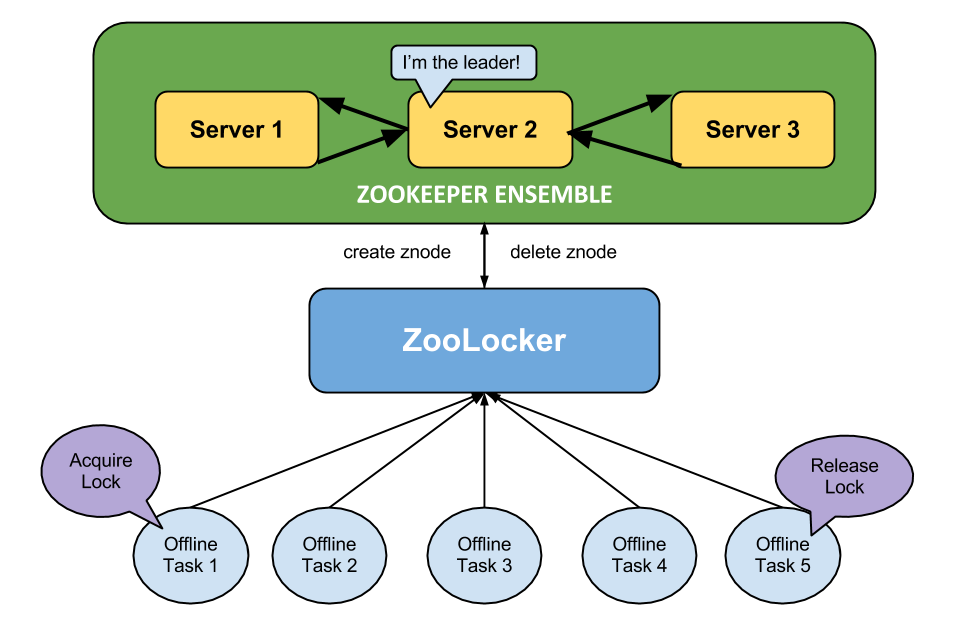
We already knew that we’d have multiple hosts running in multiple data centers, so the main question was how to get them coordinating with each other so that we would not lose messages in the event of an outage while also ensuring we would not deliver the same message multiple times. Our first thought experiment along these lines was to implement a relatively complex message passing scheme, where two hosts would subscribe to a given channel, one as the primary and one as the backup. The primary would pass a message to the backup saying that it was starting to process a message, and another when it completed. The backup would wait a certain amount of time to receive the first and then the second message from the primary. If a message failed to arrive, it would assume something had gone wrong with the primary and attempt to complete delivery to Apple’s push notification gateway.
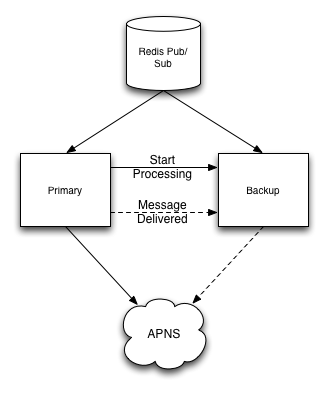
This plan had two major problems: hosts had to be aware of each other and increasing the number of hosts working in conjunction raised the complexity of ensuring reliable delivery.
We liked the idea of having one host serve as a backup for another, but we didn’t like having to coordinate the interaction between so many moving pieces. To solve this issue we went with a convention based approach. Instead of each host having to maintain a list of its partners, we just use Redis to maintain a global lock. Easy enough, right? Perhaps some code is in order!
Finally, some code!
First we create our Redis clients. We need one client for regular Redis commands we use to maintain the lock, and a separate client for Redis pub/sub commands.
var redis = require("redis");
var client = redis.createClient(config.port, config.host);
var pubsubClient = redis.createClient(config.port, config.host);
Next, subscribe to the sharded channel and set up a message handler:
// We could be subscribing to multiple shards, but for the sake of simplicity we’ll just subscribe to one here
pubsubClient.subscribe("notification_" + shard);
pubsubClient.on("message", handleMessage);
Now, the interesting part. We have multiple Node.js processes subscribed to the same Redis pub/sub channel, and each process is in a different data center. Whenever any of them receive a message, they attempt to acquire a lock for that message:
function handleMessage(channel, message) {
// Error handling elided for brevity
var payload = JSON.parse(message);
acquireLock(payload, 1, lockCallback);
}
Managing locks with Redis is made easy using the SETNX command. SETNX is a “set if not exists” primitive. From the Redis docs:
Set key to hold string value if key does not exist. In that case, it is equal to SET. When key already holds a value, no operation is performed.
If we have multiple processes calling SETNX on the same key, the command will only succeed for the process that first makes the call, and in that case the response from Redis will be 1. For subsequent SETNX commands, the key will already exist, and the response from Redis will be 0. The value we try to set with SETNX keeps track of how many attempts have been made to deliver the message, initially set to one, this allows us to retry failed messages a predefined number of times before giving up entirely.
function acquireLock(payload, attempt, callback) {
var lockIdentifier = "lock." + payload.identifier;
function dataForCallback(acquired) {
return {
"acquired" : acquired,
"lockIdentifier" : lockIdentifier,
"payload" : payload,
"attempt" : attempt
};
}
// The value of the lock key indicates how many lock attempts have been made
client.setnx(lockIdentifier, attempt, function(error, data) {
if (error) {
logger.error("Error trying to acquire redis lock for: %s", lockIdentifier);
return callback(error, dataForCallback(false));
}
return callback(null, dataForCallback(data === 1));
});
}
At this point our attempt to acquire the lock has either succeeded or failed, and our callback is invoked. What we do next depends on whether we managed to acquire the lock. If we did acquire the lock, we simply attempt to send the message. If we did not acquire the lock, then we will check back later to see if the message was sent successfully (more on this later):
function lockCallback(error, data) {
// Again, error handling elided for brevity
if (data && data.acquired) {
return sendMessage(data.payload, data.lockIdentifier, data.attempt === MAX_ATTEMPTS);
} else if (data && !data.acquired) {
return setTimeout(checkLock, LOCK_EXPIRY, data.payload, data.lockIdentifier);
}
}
Finally, it’s time to actually send the message! We do some work to process the payload into a form we can use to pass to APNS and send it off. If all goes well, we do one of two things:
- If this was our first attempt to send the message, we update the lock key in Redis to a sentinel value indicating we were successful. This is the value the backup processes will check for to determine whether or not sending succeeded.
- If this was our last attempt to send the message (i.e. the primary process failed to deliver and now a backup process is handling delivery), we simply delete the lock key.
function sendMessage(payload, lockIdentifier, lastAttempt) {
// Does some work to process the payload and generate an APNS notification object
var notification = generateApnsNotification(payload);
if (notification) {
// The APNS connection is defined/initialized elsewhere
apnsConnection.sendNotification(notification);
if (lastAttempt) {
client.del(lockIdentifier);
} else {
client.set(lockIdentifier, DONE_VALUE);
}
}
}
There’s one final piece of the puzzle: checking the lock in the process that did not acquire it initially. Here we issue a Redis GET to retrieve the current value of the lock key. If the process that won the lock managed to send the message, this key should be set to a well known sentinel value. If so, we don’t have any work to do, and we can simply delete the lock. However, if this value is not set to that sentinel value, then something went wrong with delivery in the process that originally acquired the lock and we should step up and try to deliver the message from this backup process:
function checkLock(payload, lockIdentifier) {
client.get(lockIdentifier, function(error, data) {
// Error handling elided for brevity
if (data !== DONE_VALUE) {
acquireLock(payload, data + 1, lockCallback);
} else {
client.del(lockIdentifier);
}
});
}
Summing Up
So, there you have it in a nutshell. This method of coordinating between processes makes it very easy to adjust the number of processes subscribing to a given shard’s channels. There’s no need for any process subscribed to a channel to be aware of how many other processes are also subscribed. As long as we have at least two processes in separate data centers subscribing to each shard we are protected from all of the from the following scenarios:
- The crash of any individual Node.js process
- The loss of a single host running the Node.js processes
- The loss of an entire data center containing many hosts running the Node.js processes
Let’s go back over our initial goals and see how we fared:
- Impact to normal page serving times should be minimal
We accomplish this by minimizing the workload done as part of the normal browser-driven request/response processing. The deferred task system picks up from there, out of band.
- Delivery should be in near-real time
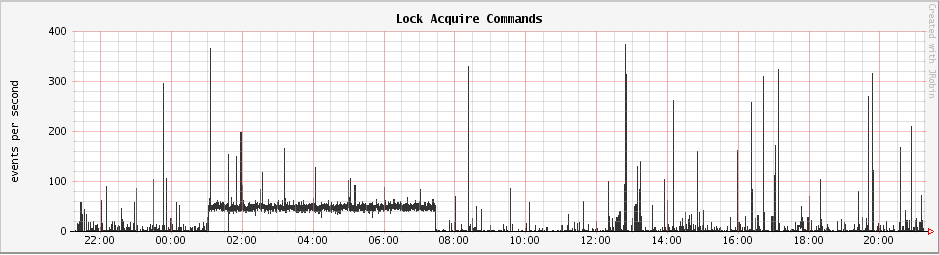
Processing stats from our implementation show that time from user actions leading to event generation to message delivery averages about 400ms and is completely event driven (no polling).
- Handle thousands of notifications per second
In stress tests of our system, we were able to process more than 2,000 notifications per second on a single host (8 Node.js workers, each subscribing to multiple shards).
- The underlying services should be highly available
The availability design is resilient to a variety of failure scenarios, and failover is automatic.
We hope you’re enjoying push notifications in the new Flickr iPhone app.
Addendum!
There was a minor problem with the code in this post when supporting more than two workers. For a full explanation of the problem and the solution, check out Global Redis Locks Redux.

Like this post? Have a love of online photography? Want to work with us? Flickr is hiring engineers, designers and product managers in our San Francisco office. Find out more at flickr.com/jobs.