At the Emerging Technology conference this year Stamen Design’s Michal Migurski and Shawn Allen led an afternoon workshop called “Maps from Scratch: Online Maps from the Ground Up” where people made digital maps from, well… scratch.
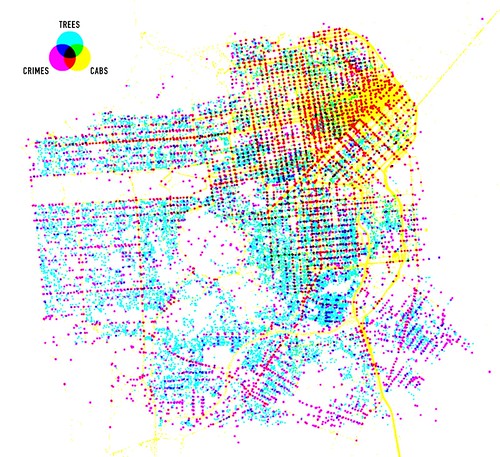
If you’ve never heard of Stamen they’ve been doing some of the most exciting work around the idea of “custom cartography” including: Cabspotting, Oakland Crimespotting and Old Oakland Maps, work for the London Olympics, and designing custom map tiles for CloudMade. (Stamen also built the recently launched Flickr Clock :-)
All of this is interesting in its own right; proof that there is still a lot of room in which to imagine maps beyond so-called red-dot fever. All of this is extra interesting in light of Apple’s recent announcement to allow developers to define their own map tiles in the next iPhone OS release. All of this super-duper interesting because it is work produced by a team of less than 10 people.
The tools, and increasingly the data, to build the maps we want are bubbling up and becoming easier and more accessible to more people every day. Easier, anyway.
“One of the things that made this tutorial especially interesting for us was our use of Amazon’s EC2 service, the “Elastic Compute Cloud” that provides billed-by-the-hour virtual servers with speedy internet connections and a wide variety of operating system and configuration options. Each participant received a login to a freshly-made EC2 instance (a single server) with code and lesson data already in-place. We walked through the five stages of the tutorial with the group coding along and making their own maps, starting from incomplete initial files and progressing through added layers of complexity.
“Probably the biggest hassle with open source geospatial software is getting the full stack installed and set up, so we’ve gone ahead and made the AMI (Amazon Machine Image, a template for a virtual server) available publicly for anyone to use, along with notes on the process we used to create it.”
— Michal Migurski
The Maps From Scratch (MFS) AMI may not be a Leveraged Turn Key Synergistic Do-What-I-Mean Solutions Platform but, really, anything that dulls the hassle and cost of setting up specialized software is a great big step in the right direction. I mention all of this because Clustr, the command-line application we use to derive shapefiles from geotagged photos, has recently been added to the list of tools bundled with the MFS AMI.
Specifically: ami-4d769124.
We’re super excited about this because it means that Clustr is that much easier for people to use. We expressly chose to make Clustr an open-source project to share some of the tools we’ve developed with the community but it has also always had a relatively high barrier to entry. Building and configuring a Unix machine is often more that most people are interested in, let alone compiling big and complicated maths libraries from scratch. Clustr on EC2 is not a magic pony factory but hopefully it will make the application a little friendlier.
Creating and configuring an EC2 account is too involved for this post but there are lots of good resources out there, starting with Amazon’s own documentation. When I’m stuck I usually refer back to Paul Stamatiou’s How To: Getting Started with Amazon EC2.
Assuming that you familiar using Unix command line tools, let’s also assume that you have gotten all your ducks in a row and are ready to fire up the MFS AMI:
your-computer> ec2-run-instances ami-4d769124 -k example-keypair
your-computer> ec2-describe-instances
At which point, you’ll see something like this:
INSTANCE i-xxxxxxxx ami-4d769124 ec2-xxxxx.amazonaws.com blah blah blah
i-xxxxxxxx is the unique identifier of your current EC2 session. You will need this to tell Amazon to shut down the server and stop billing you for its use.
ec2-xxxxx.amazonaws.com is the address of your EC2 server on the Internets.
Once you have that information, you can start using Clustr. First, log in and create a new folder where you’ll save your shapefile:
your-computer> ssh -i example-rsa-key root@ec2-xxxxx.amazonaws.com
ec2-xxxxx.amazonaws.com> mkdir /root/clustr-test
The MFS AMI comes complete with a series of sample “points” files to render. We’ll start with the list of all the geotagged photos uploaded to Flickr on March 24:
ec2-xxxxx.amazonaws.com> /usr/bin/clustr -v -a 0.001
/root/clustr/start/points-2009-03-24.txt
/root/clustr-test/clustr-test.shp
By default Clustr generates a series of files named clustr (dot shp, dot dbf and dot shx because shapefiles are funny that way) in the current working directory. You can specify an alternate name by passing a fully qualified path as the last argument to Clustr. When run in verbose mode (that’s the -v flag) you’ll see something like this:
Reading points from input.
Got 44410 points for tag '20090324'.
799 component(s) found for alpha value 0.001.
- 23 vertices, area: 86.7491, perimeter: 71.9647
- 32 vertices, area: 1171.51, perimeter: 41.3095
- 8 vertices, area: 18.5112, perimeter: 0.529504
- 12 vertices, area: 1484.81, perimeter: 10.8544
...
Writing 505 polygons to shapefile.
Yay!
ec2-xxxxx.amazonaws.com> ls -la /root/clustr-test
total 172
drwxr-xr-x 2 root root 4096 2009-04-07 03:14 .
drwxr-xr-x 5 root root 4096 2009-04-07 02:22 ..
-rw-r--r-- 1 root root 52208 2009-04-07 03:14 clustr-test.dbf
-rw-r--r-- 1 root root 97388 2009-04-07 03:14 clustr-test.shp
-rw-r--r-- 1 root root 4140 2009-04-07 03:14 clustr-test.shx
Now copy the shapefiles back to your computer and terminate your EC2 instance (or you might be surprised when you get your next billing statement from Amazon).
ec2-xxxxx.amazonaws.com> scp -r /root/clustr-test
you@your-computer:/path/to/your/desktop/
ec2-xxxxx.amazonaws.com> exit
your-computer> ec2-terminate-instances i-xxxxxxxxx
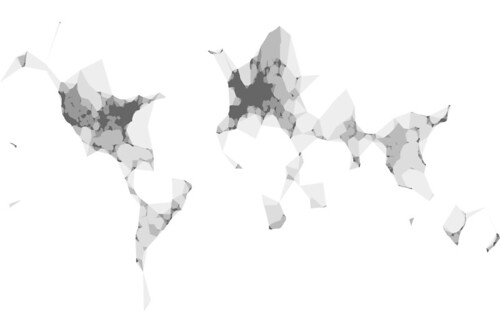
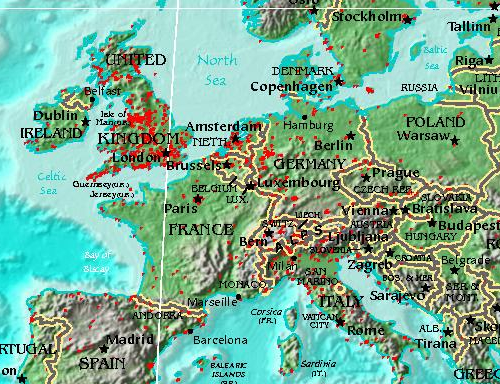
I created this image (using the open source QGIS application) for all those points by running Clustr multiple times with alpha numbers ranging from 0.05 to 603:
Here’s another version rendered using the nik2img application and a custom style sheet, both included with the MFS distribution:
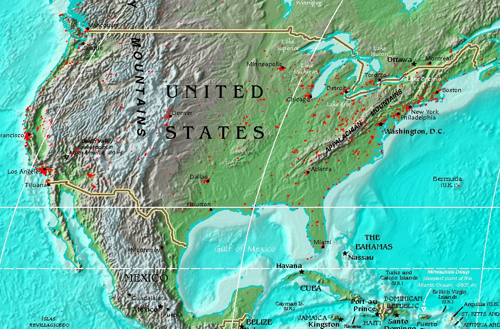
Here’s one of all the geotagged photos tagged “route66” (with alpha numbers ranging from 0.001 to 0.5):

Apologies and big sloppy kisses to Stamen’s own Mappr (first released in 2005).
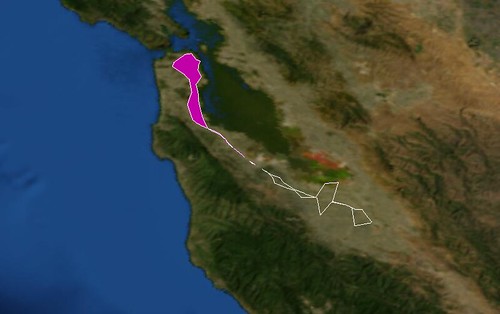
Or tagged “caltrain“, the commuter train that runs between San Francisco and San Jose:
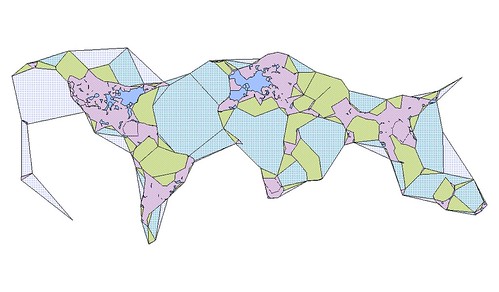
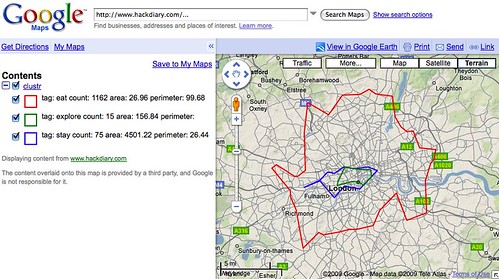
Meanwhile, Matt Biddulph at Dopplr has been generating a series of visualizations depicting the shape of where to eat, stay and explore for the cities in their Places database. This is what London looks like:
Or: “London dopplr places, filtered to only places my social network has been to, clustrd“.
One of the things I like the most about Clustr is that it will generate shape(file)s for any old list of geographic coordinates. Now that most of the hassle of setting up Clustr has been (mostly) removed, the only question left is: What do you want to render?
“They do not detail locations in space but histories of movement that constitute space.”
— Rob Kitchin, Chris Perkins
If you’re like me you’re probably thinking something like “Wouldn’t it be nice if I could just POST a points file to a webservice running on the AMI and have it return a compressed shapefile?” It sure would so I wrote a quick and dirty version (not included in the MFS AMI; you’ll need to do that yourself) in PHP but if there are any Apache hackers in the house who want to make a zippy C version that would be even Moar Awesome ™.
If you don’t want to use the MFS AMI and would rather just install Clustr on your own machine instance, here are the steps I went through to get it work on a Debian 5.0 (Lenny) AMI; presumably the steps are basically the same for any Linux flavoured operating system:
$> apt-get update
$> apt-get install libcgal-dev
$> apt-get install libgdal1-dev
$> apt-get install subversion
$> svn co http://code.flickr.com/svn/trunk/clustr/
$> cd clustr
$> make
$> cp clustr /usr/bin/
$> clustr -h
clustr 0.2 - construct polygons from tagged points
written by Schuyler Erle
(c) 2007-2008 Yahoo!, Inc.
Usage: clustr [-a <n>] [-p] [-v] <input> <output>
-h, -? this help message
-v be verbose (default: off)
-a <n> set alpha value (default: use "optimal" value)
-p output points to shapefile, instead of polygons
If <input> is missing or given as "-", stdin is used.
If <output> is missing, output is written to clustr.shp.
Input file should be formatted as: <tag> <lon> <lat>n
Tags must not contain spaces.
Just like that!